🎓 レベル:標準 | 重要度:B(標準)
📎 前提:アンサンブルの原理 | 関連:訓練・検証・テストと交差検証(out-of-fold)
要点(BLUF)
- スタッキング(stacked generalization)は、異種の強いモデル(ロジスティック回帰・ランダムフォレスト・GBDT・k近傍法など)の予測を「新しい特徴」として、その上にメタモデルを載せて最終予測を学習する2段構成のアンサンブルです。
- 最重要は、メタモデルの訓練特徴を out-of-fold(OOF)予測で作ること。ベースモデルが自分の学習に使っていないデータに対して出した予測だけを集める。これを怠ると情報リークが起き、メタモデルが過学習します。
- バギング・ブースティングが「同種の弱学習器」を束ねるのに対し、スタッキングは「異種の強学習器」を束ねる。だからベース同士の**誤りが相関しない(多様)**ほど効きます(アンサンブルの原理)。
1. スタッキングとは:2段で「組み合わせ方」を学習する
多数決や単純平均(アンサンブルの原理)は、各モデルの予測をあらかじめ決めた固定の式で混ぜます。スタッキングはここを賢くして、「どう混ぜれば一番当たるか」自体をデータから学習します。
構成は2段です。1段目(level-0)に複数の異なるベースモデルを並べ、2段目(level-1)にそれらの予測を入力として受け取るメタモデルを置きます。
flowchart TB
X["入力特徴 x"]
X --> M1["level-0:ロジスティック回帰"]
X --> M2["level-0:ランダムフォレスト"]
X --> M3["level-0:GBDT"]
X --> M4["level-0:k近傍法"]
M1 --> Z["メタ特徴 z = 各モデルの予測値を並べたベクトル"]
M2 --> Z
M3 --> Z
M4 --> Z
Z --> Meta["level-1:メタモデル(例:ロジスティック回帰)"]
Meta --> Yhat["最終予測 y_hat"]
ベースモデルが 個あるとき、1点 に対して各モデルが予測 を出します。これを並べたものがメタ特徴です:
メタモデル は、この から正解 を当てるように学習します。最終予測は
要するに:元の特徴 をいったん「各モデルの予測」という 次元の新しい座標 に変換し、その空間で改めて回帰/分類を解き直すのがスタッキングです。メタモデルは「どのベースを、どの場面で、どれだけ信用するか」を学びます。
分類のメタ特徴には、ハードな予測ラベルよりもクラス確率(
predict_proba)を使うのが定石です。確率のほうが情報量が多く、メタモデルが各ベースの自信度まで使えるためです。
2. なぜ単純な訓練データ予測ではダメか(リーク問題)
ここがスタッキングの肝で、最も間違えやすい点です。
素朴に考えると、「ベースモデルを全訓練データで学習させ、同じ訓練データに対する予測をメタ特徴にすればいい」と思えます。これは致命的に間違いです。
問題は、ランダムフォレストや GBDT のような強いモデルは自分が学習に使った点をほぼ丸暗記できること。だから訓練データ上の予測 は、本来の汎化性能よりもずっと正確に見えます。
flowchart TB
A["全訓練データでベースを学習"] --> B["同じ訓練データで予測"]
B --> C["予測がほぼ正解と一致(丸暗記の影響)"]
C --> D["メタモデルが「ベースは常に正しい」と誤学習"]
D --> E["本番(未知データ)では性能が崩れる:過学習"]
メタモデルから見ると、訓練時には「ベースの予測 ≒ 正解」という本番では再現されない関係を学んでしまいます。これが情報リーク(leakage) で、訓練スコアは異常に良いのに本番でガクッと落ちる、という典型的な過学習を生みます。
要するに:メタモデルを正しく鍛えるには、ベースが学習に使っていないデータでの予測を見せなければなりません。本番では必ず「未知の点」に対して予測するのだから、訓練段階でもその状況を再現する必要があります。これを実現する仕組みが次の OOF 予測です。
3. out-of-fold(OOF)予測でメタ特徴を作る
解決策は、交差検証(訓練・検証・テストと交差検証)の仕組みを流用して、各点に対し「その点を学習に使わなかったベースモデル」の予測を割り当てることです。こうして集めた予測を out-of-fold(OOF)予測と呼びます。
手順(-fold、ベースモデル1個あたり):
flowchart TB
Split["訓練データを K 個の fold に分割"]
Split --> Loop["各 fold k について繰り返す"]
Loop --> Train["fold k 以外(K-1 個)でベースを学習"]
Train --> Pred["学習に使わなかった fold k を予測"]
Pred --> Store["その予測を fold k の点の OOF 値として保存"]
Store --> Check{"全 fold を処理した ?"}
Check -->|"No"| Loop
Check -->|"Yes"| Done["全訓練点に OOF 予測がそろう(リークなし)"]
ポイントは、fold の点に対する予測は、必ず fold を除いて学習したモデルが出していること。どの点も「自分を見ていないモデル」の予測を受け取るので、本番(未知データ)の状況と同じになります。これを全ベースモデルについて行い、 本の OOF 予測列を横に並べれば、リークのないメタ特徴行列が完成します。
数式で言うと、点 が fold に属するとき、ベース の OOF 予測は
ここで は「fold を除いて学習したベース 」を表します。メタモデルはこの で学習します。
要するに:OOF 予測は「交差検証のホールドアウト予測を全 fold ぶん集めて、訓練データ全点ぶんの“正直な”予測列を作る」操作です。各点が必ず自分を見ていないモデルに採点されるので、メタモデルがリークで過学習するのを防げます。
推論時(本番)はどうするか
学習が済んだら、本番予測のためにベースモデルを全訓練データで学習し直します(fold で分ける必要はもうない)。新しい点 には、この「全データ学習版」のベースが予測を出し、それを並べた をメタモデルに通します。
flowchart LR
New["新しい点 x"] --> Base["全データで再学習したベース群が予測"]
Base --> Zx["メタ特徴 z(x)"]
Zx --> G["メタモデル g"]
G --> Out["最終予測"]
要するに:OOF はあくまで「メタモデルを正しく訓練するための仕掛け」。本番のベースは全データで鍛えた最強版を使い、メタモデルだけが OOF で学んだ「混ぜ方」を適用します。
4. ブレンディング(blending)との違い
ブレンディングは、OOF を作る代わりにホールドアウト1枚でメタ特徴を作る簡易版です。
- 訓練データを「ベース学習用」と「ブレンド用(例:10〜15%)」に分ける
- ベースをベース学習用だけで学習し、ブレンド用に対する予測をメタ特徴にする
- メタモデルはそのブレンド用の予測と正解で学習する
flowchart TB
subgraph Stk["スタッキング(OOF)"]
S1["K-fold で全訓練点ぶんの予測を生成"]
S1 --> S2["全データを使える/実装は重め"]
end
subgraph Bld["ブレンディング(ホールドアウト)"]
B1["訓練を2分割し片方の予測だけ使用"]
B1 --> B2["実装が単純/使うデータが少なく予測が不安定"]
end
両者ともリークは防げます(ベースが見ていないデータの予測を使う点は同じ)。違いはデータ効率です。
| スタッキング(OOF) | ブレンディング(ホールドアウト) | |
|---|---|---|
| メタ特徴の作り方 | -fold の全 fold 予測を結合 | ホールドアウト1枚の予測のみ |
| 使えるデータ | 全訓練データがメタ学習に回る | 一部(ホールドアウト分)だけ |
| 実装の手間 | 重い(fold ループが必要) | 軽い(1回の分割だけ) |
| メタ学習信号 | 全点ぶんで安定 | 少量でノイズが多く、メタが過学習しやすい |
要するに:ブレンディングは「OOF の手抜き版」。実装が楽な代わりに、メタモデルが少量のデータでしか学べず、ノイズに振り回されやすい。データに余裕がなければスタッキング(OOF)のほうが安全です。Kaggle 等では実装の手軽さからブレンディングも使われますが、原理的に上位互換なのは OOF スタッキングです。
5. メタモデルは単純なものが定石
メタモデルには線形回帰・ロジスティック回帰・リッジ回帰のような単純で正則化の効くモデルを使うのが定石です。GBDT のような強いモデルをメタに置くのは、むしろ過学習を招きやすく避けられます。
理由は3つあります。
- 重い仕事はベースが終えている。ベースは既に複雑な非線形パターンを捉えており、メタモデルの仕事は「どのベースをどれだけ信じるか」という重みづけだけ。これは線形モデルで十分表現できます。
- 入力が低次元。メタ特徴は 次元(ベースの数ぶん)しかなく、しかも互いに相関が強い(みな同じ を予測している)。この狭く相関した空間で複雑なモデルを使うと過学習します。
- 正則化で安定する。リッジ(L2)を使えば、特定のベース1つに重みが集中するのを防げ、全ベースをバランス良く使えます。
ロジスティック回帰をメタに使うと、最終予測は各ベース予測の重み付き和をシグモイドに通した形になります:
学習された重み は「ベース をどれだけ信用するか」を表します。役に立たないベースには小さい(あるいは負の)重みがつき、自動的に重要度が調整されます。
要するに:スタッキングは「重み付き多数決を、固定値ではなくデータから学ぶ」こと。重みを学ぶだけなら線形モデルで足り、複雑なメタは過学習するだけ、というのが定石の背景です。
6. 位置づけ:なぜ異種・多様なベースが効くのか
バギング・ブースティングとの最大の違いは、束ねる部品の種類です。
graph TB
Ens["アンサンブル"]
Ens --> Homo["同種の弱学習器を束ねる"]
Ens --> Hetero["異種の強学習器を束ねる"]
Homo --> Bag["バギング/ランダムフォレスト:並列・バリアンス低減"]
Homo --> Boost["ブースティング:逐次・バイアス低減"]
Hetero --> Stk["スタッキング:メタモデルが混ぜ方を学習"]
- バギング/ランダムフォレスト(バギングとランダムフォレスト):同じ種類の木をたくさん作り平均してバリアンスを下げる。
- ブースティング/AdaBoost(ブースティングとAdaBoost):同じ種類の弱学習器を逐次に積み、前の誤りを補正してバイアスを下げる。
- スタッキング:異なるアルゴリズム(線形・木・距離ベース・NN など)を並べ、メタモデルがそれらの混ぜ方を学ぶ。
なぜ「異種」が効くのか。アンサンブルの原理 の核心は「誤りが相関しないモデルを混ぜるほど、平均化で誤差が打ち消し合う」ことでした。アルゴリズムが違えば帰納バイアス(前提とする仮定)が違うので、間違える場面が互いにずれます。
- ロジスティック回帰は線形な境界を仮定し、線形では捉えられない場所で外す
- 決定木系は軸平行な境界しか引けず、斜めの境界で外す
- k近傍法は局所の密度に依存し、疎な領域で外す
これらは別々の場面で外すので、誤りの相関が低い。メタモデルは「この領域では木を、あの領域では線形を信じる」と使い分けられます。逆に、よく似たモデル(例:少しだけ違うランダムフォレストを5個)を並べても誤りが揃っていて、混ぜる旨味がありません。
要するに:スタッキングの効き目はベースの多様性で決まります。性能が同程度でも異なる種類で、異なる間違い方をするモデルを集めるのがコツです。「強いが似たモデル」より「そこそこでも違う角度から見るモデルの集合」のほうが効きます。
⚠️ よくある誤解・落とし穴
- 「ベースの訓練データ予測をそのままメタ特徴にすればいい」は最大の罠。強いベースは訓練点を丸暗記するため、リークでメタが過学習します。必ず OOF 予測(または最低でもブレンディングのホールドアウト)を使う。
- 「メタモデルは高性能なほど良い」ではない。メタに GBDT などを置くと、低次元で相関の強いメタ特徴を過学習します。線形・ロジスティック・リッジが定石。
- 「ベースは強くて正確なほど良い」だけではない。同じくらい大事なのが多様性。誤りが相関しないベースを集めないと、いくら個々が強くても混ぜる効果が出ません。
- 「スタッキングは必ず単一モデルに勝つ」とは限らない。ベースが似ていたり、メタが過学習したり、データが少なければ、最良の単一モデルに負けることもあります。改善幅は多くの場合わずかで、運用の複雑さ(複数モデルの保守・推論コスト)と引き合うかは要検討です。
- 「ブレンディングとスタッキングは同じ」ではない。リーク回避という目的は同じですが、ブレンディングはホールドアウト1枚しか使わずデータ効率が劣り、メタ学習信号がノイジーです。
- 多段スタッキング(メタの上にさらにメタ)は過学習リスクが急増する。実務では2段(level-0 と level-1)で止めるのが無難です。
対応するシミュレーション
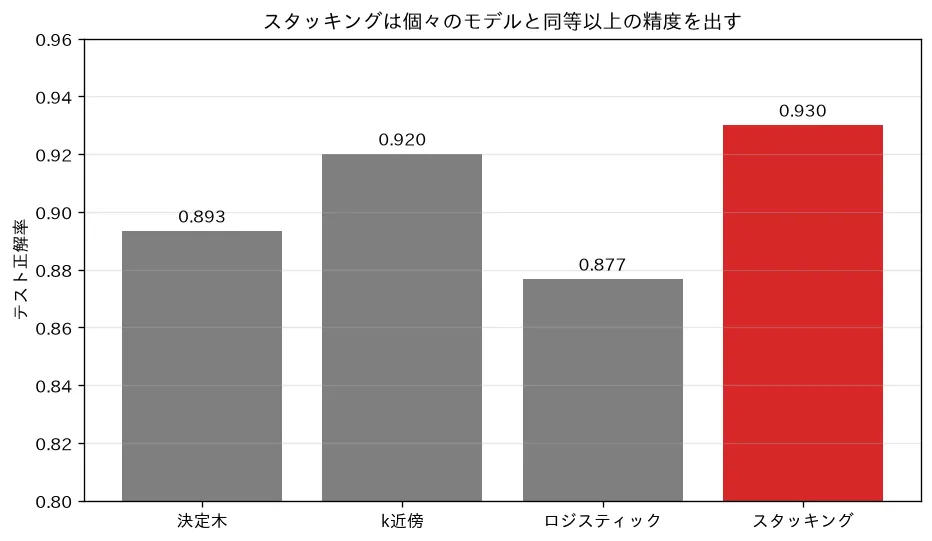
simulations/stacking.py:種類の違う base モデル(決定木・k近傍・ロジスティック)の予測を新しい特徴にし、その上にメタモデル(ロジスティック回帰)を載せるスタッキングを行います。個々のモデル(最良0.92)よりアンサンブル(0.93)が良くなること、そして base の予測はリーク防止のため交差検証の out-of-fold 予測で作ることを示します。脱相関した多様なモデルをそろえるのがコツです(アンサンブルの原理)。
関連ノート
- アンサンブル学習 目次
- アンサンブルの原理(多様性・誤りの脱相関がなぜ効くか)
- バギングとランダムフォレスト(同種・並列・バリアンス低減との対比)
- ブースティングとAdaBoost(同種・逐次・バイアス低減との対比)
- 訓練・検証・テストと交差検証(OOF 予測の土台となる交差検証)
- 機械学習テキスト 全体目次