🎓 レベル:標準 | 重要度:B(標準)
📎 前提:畳み込みニューラルネットワーク | 関連:重み初期化と正規化(BatchNorm)
要点(BLUF)
- CNNは LeNet → AlexNet → VGG → GoogLeNet → ResNet と「より深く・より効率よく」進化してきました。各世代は ImageNet コンペ(ILSVRC)の勝者として登場します。
- ただ層を増やすと 劣化問題(degradation) にぶつかります。これは過学習ではなく「深い方が訓練誤差まで悪化する」最適化の壁です。
- ResNet の 残差接続(skip connection) がこの壁を壊し、100層超の学習を可能にしました。本ノートの中心はここです。
1. CNNアーキテクチャの発展史
まず系統を1枚で押さえます。横軸は登場年、縦軸はおおよその深さ(層数)です。
graph LR
A["LeNet (1998)<br>5層・手書き数字"] --> B["AlexNet (2012)<br>8層・ReLU/Dropout/GPU"]
B --> C["VGG (2014)<br>16〜19層・3×3を積む"]
B --> D["GoogLeNet (2014)<br>22層・Inception"]
C --> E["ResNet (2015)<br>残差接続で152層"]
D --> E
E --> F["その後 (要最新確認)<br>EfficientNet・ConvNeXt 等"]
各世代の「何が新しかったか」を要点で並べます。
| 世代 | 年 | 鍵となる発明 | ひとことで |
|---|---|---|---|
| LeNet-5 | 1998 | 畳み込み+プーリングの原型 | 手書き数字(郵便番号)認識の初期CNN |
| AlexNet | 2012 | ReLU・Dropout・GPU学習・データ拡張 | ImageNetで圧勝し深層学習ブームの引き金 |
| VGG | 2014 | 3×3畳み込みだけを深く積む | 単純さと深さ。設計指針が明快 |
| GoogLeNet / Inception | 2014 | Inceptionモジュール・1×1畳み込み | マルチスケールかつ少パラメータ |
| ResNet | 2015 | 残差接続(skip connection) | 超深層(152層)を学習可能に |
LeNet(1998)— 原型
畳み込み層とプーリング層を交互に積み、最後に全結合層で分類する、という現在まで続く基本骨格を最初に確立したのが LeNet-5 です。手書き数字(MNIST的なタスク)向けで、規模は5層程度。当時は計算資源とデータが足りず、これ以上は広がりませんでした。
AlexNet(2012)— ブームの引き金
LeNetを大規模化したのが AlexNet です。重要なのは規模だけでなく、後の標準となる工夫を導入した点です。
- ReLU 活性化:。飽和しないので深い層でも勾配が流れやすい(→ 活性化関数)
- Dropout:全結合層の過学習抑制(→ ニューラルネットの正則化)
- GPU で学習:大規模学習を現実的な時間に
- データ拡張:画像の反転・切り抜きで実質的にデータを増やす
これらが噛み合って ImageNet で誤差を大幅に下げ、「深層学習は効く」と業界全体が動き出しました。
VGG(2014)— 3×3を深く積む
VGGの主張は明快で「大きいフィルタを使わず、3×3だけを深く積めばよい」というものです。なぜそれで十分かは受容野(receptive field)の計算でわかります。
- 3×3畳み込みを 2層 積むと、受容野は 5×5 に等しい
- 3層積むと 7×7 に等しい
そのうえでパラメータ数を比べると:
要するに、同じ広さを見ながらパラメータが少なく、しかも非線形(ReLU)を挟む回数が増えるので表現力も上がります。「小さいフィルタを積む」は以後の設計の定番になりました。
GoogLeNet / Inception(2014)— マルチスケール+1×1
VGGが「深さ」で攻めたのに対し、GoogLeNet は「1つの層の中で複数のフィルタサイズを並列に使う」発想です。これが Inceptionモジュール で、1×1・3×3・5×5の畳み込みとプーリングを並列に走らせ、出力を結合します。狙いは、対象の大きさ(スケール)がまちまちでも同じ層で拾えるようにすることです。
ただし並列に大きい畳み込みを走らせると計算量が爆発します。そこで効くのが 1×1畳み込み です。役割は2つ:
- 次元削減(ボトルネック):チャネル数を 1×1 で先に圧縮してから 3×3・5×5 に渡す → 計算量を大幅に削減
- 非線形の追加:1×1の後にもReLUを挟めるので表現力が増す
この工夫で、GoogLeNet はパラメータ数を AlexNet より大幅に減らしながら(おおよそ1桁規模)高精度を達成しました。
graph TD
IN["入力特徴マップ"] --> R1["1×1 畳み込み<br>(次元削減)"]
IN --> R2["1×1 畳み込み<br>(次元削減)"]
IN --> P["3×3 プーリング"]
IN --> C1["1×1 畳み込み"]
R1 --> C3["3×3 畳み込み"]
R2 --> C5["5×5 畳み込み"]
P --> P1["1×1 畳み込み<br>(次元削減)"]
C1 --> CAT["チャネル方向に結合<br>(concat)"]
C3 --> CAT
C5 --> CAT
P1 --> CAT
1×1畳み込みは「空間サイズは変えずチャネルだけ混ぜる・減らす」操作です。詳しくは 畳み込みニューラルネットワーク のチャネルの考え方を参照してください。
理解確認(軽く):VGGが「3×3を2層」で5×5の受容野を作るのに、なぜわざわざ5×5を1枚使わないのでしょう?
2. 「深くする」ことの困難 — 劣化問題
ここが ResNet を理解する核心です。素朴には「層を増やすほど表現力が上がり精度も上がる」はずですが、実際には ある深さを超えると精度が頭打ちになり、さらに深くすると悪化 します。
重要なのは、これが 過学習ではない ことです。過学習なら「訓練誤差は下がるのにテスト誤差が上がる」はずですが、劣化問題では 訓練誤差そのものが、浅いモデルより悪化 します。つまり「学習しきれていない」=最適化の問題です。
なぜおかしいか。深い方が損なはずがない、という論理があります。
18層モデルがある解に到達できたとする。34層モデルは、その18層分をコピーし、残り16層を**恒等写像(何もしない層)**にすれば、原理上まったく同じ性能を出せる。
つまり深いモデルは浅いモデルの解を「内包」できるのだから、少なくとも同等以上になれるはずです。にもかかわらず実際は悪化する。これは「恒等写像を学ぶ」という一見簡単なことを、通常の積層(plain network)では SGD がうまく見つけられないことを意味します。
xychart-beta
title "劣化問題(イメージ:訓練誤差)"
x-axis ["浅い", "中", "深い", "超深い"]
y-axis "訓練誤差" 0 --> 10
line [8, 5, 4, 7]
図の意味:深くするほど誤差が単調に下がるのではなく、ある点を超えると訓練誤差まで上向く。これが劣化問題です。
勾配消失(誤差逆伝播法)も一因ですが、BatchNorm 等で勾配消失を抑えてもこの劣化は残ることが報告されました。**問題の本質は「恒等写像の学習しにくさ」**にあります。
3. ResNet — 残差接続(skip connection)
定式化
ResNet のアイデアは、層に「望ましい出力 をそのまま学ばせる」のではなく、入力 からのズレ(残差)だけを学ばせることです。数本の積層が学ぶ関数を とし、その出力に入力 を足し戻します。
ここで が 残差関数(residual)、 が ショートカット接続(skip / shortcut connection) です。学習で更新されるのは の重みであり、 は加算で迂回して直接運ばれます。
要するに:層に「正解そのもの」ではなく「正解と入力の差分」を作らせ、最後に入力を足して帳尻を合わせる構造です。
graph TD
X["入力 x"] --> W1["重み層 (3×3 conv)"]
W1 --> RELU1["ReLU"]
RELU1 --> W2["重み層 (3×3 conv)"]
W2 --> ADD(("+"))
X -- "ショートカット(恒等)" --> ADD
ADD --> RELU2["ReLU"]
RELU2 --> OUT["出力 H(x) = F(x) + x"]
なぜこれで劣化問題が解けるのか(理論的裏付け)
ポイントは「恒等写像が最適なケースを、ほぼタダで表現できる」ことです。
- もしその層では何もしない(恒等写像 )のが最適なら、通常の積層は重みを調整して をゼロから作り込まねばなりません。これは前述のとおり SGD には難しい。
- 残差形式なら は と等価です。重みを0付近に押し込むだけでよく、これは初期化(重みは0近傍から始まる)とも相性が良く、はるかに学習が容易です。
要するに:「何もしない」を表すのが、ゼロを作る作業に化けるので簡単になる。これで「深いモデルは浅いモデル+恒等で同等以上になれるはず」という理屈が、実際に最適化で達成できるようになります。
もう一つの効果が 勾配の近道 です。逆伝播では、加算ノードは勾配をそのまま両側に流します。 の出力に届いた勾配 は、ショートカット側を通って を一切経由せず 入力 へ直接届きます。
要するに:勾配の式に必ず「」が残ります。 が小さく潰れても、この のおかげで勾配が0になりにくい。だから深い層にも更新信号が届き、勾配消失(誤差逆伝播法)が緩和されます。
この2点(恒等の作りやすさ+勾配の近道)で、ResNet は 152層 という当時桁違いの深さを安定して学習し、しかも VGG より計算量が小さいまま ImageNet の精度を更新しました。残差を積み上げる 残差ブロック(residual block) が基本部品で、これを多数重ねたものが ResNet-34/50/101/152 です。
BatchNorm との組み合わせ
ResNet は残差接続だけで動くわけではなく、各畳み込みの後に バッチ正規化(BatchNorm) を挟みます。BatchNorm は各層の入力分布を整え、勾配のスケールを安定させて学習を速め、深いネットを訓練しやすくします(詳細は 重み初期化と正規化)。
役割分担をひとことで:
- 残差接続:恒等を学びやすくし、勾配の近道を作る(最適化の「経路」を確保)
- BatchNorm:各層の信号スケールを整える(最適化の「足場」を安定化)
この2つが噛み合って初めて、超深層の安定学習が成立します。どちらか一方では不十分です。
4. その後(要最新確認)
ResNet 以降も改良は続いています。急速に動く領域なので、最新の比較は要最新確認 として扱ってください。代表例だけ挙げます。
- EfficientNet(2019):深さ・幅・入力解像度をバランスよく同時にスケールする(複合スケーリング)方針。少ない計算量で高精度を狙う系統です。
- ConvNeXt(2022):ResNet を出発点に、Vision Transformer の設計(大きめカーネル、GELU、正規化の見直し等)を少しずつCNNへ取り込んで近代化したもの。「Transformerに対抗できる純CNN」として注目されました。
これらは Transformer(Attention系)との対比で理解すると位置づけが見えます。「CNN対Transformer」は今も決着していない論点で、タスク・データ規模・計算予算で使い分けるのが実務です。
⚠️ よくある誤解・落とし穴
- 「残差接続=ただのスキップ(ショートカット)」ではない。本質は「恒等写像が最適なとき にするだけで済む」という学習のしやすさにあります。スキップで値を運ぶこと自体より、最適化問題を易しく書き換えたことが効いています。
- 「深ければ深いほど良い」ではない。残差接続は深さの上限を引き上げますが、無限に精度が上がるわけではありません。データ量・計算予算・タスクに対して適切な深さがあります。深さは手段であって目的ではありません。
- 劣化問題=過学習、ではない。劣化問題は訓練誤差が悪化する最適化の問題です。テスト誤差だけが悪化する過学習(ニューラルネットの正則化の対象)とは原因が違います。
- 1×1畳み込みは「無意味な恒等」ではない。空間サイズは変えませんが、チャネル方向に線形結合+非線形を入れるので、次元削減と表現力追加の両方に効きます。
- 残差接続は CNN 専用ではない。同じ発想は Transformer など他のアーキテクチャでも標準採用されています(Transformer)。「深いネットを学習可能にする一般的な部品」と捉えるのが正確です。
対応するシミュレーション
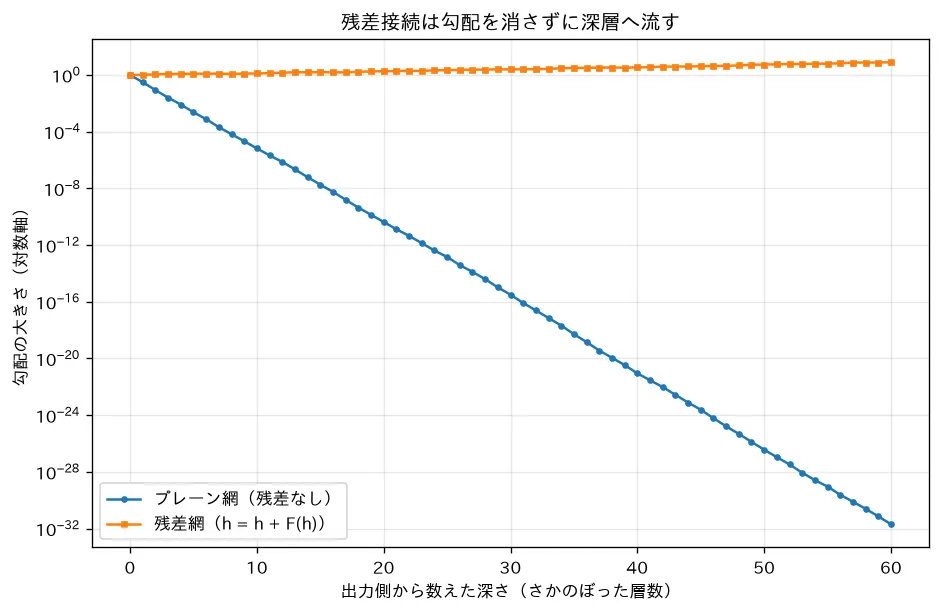
simulations/resnet_gradient.py:層を素朴に重ねた「プレーン網」と、残差接続 を入れた「残差網」で、逆伝播の勾配が深さとともにどうなるかを比べます。プレーン網は各層のヤコビアンが掛かり続けて勾配が指数的に消える(劣化問題)のに対し、残差網はヤコビアンが になり恒等写像 の経路を通って勾配が に保たれることを対数軸で可視化します。これが ResNet が超深層を学習可能にした理由で、Transformer もブロックごとに残差を使います(Transformer)。
関連ノート
- 深層学習アーキテクチャ 目次 — このドメインの目次
- 畳み込みニューラルネットワーク — CNNの基本(畳み込み・プーリング・チャネル)
- 重み初期化と正規化 — BatchNorm の役割
- ニューラルネットの正則化 — Dropout・過学習対策
- 機械学習テキスト 全体目次 — 機械学習テキスト全体のハブ