🎓 レベル:標準 | 重要度:A(必須)
📎 前提:LLMの全体像 | 数理:最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論)(統計・最尤)
要点(BLUF)
- 事前学習(pretraining) は、大規模なテキストコーパスで「次トークン予測」をひたすら解く工程です。ラベルは要らず(自己教師あり)、損失は交差エントロピー=負の対数尤度——つまり正体は最尤推定(最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) 統計)です。
- スケーリング則(scaling laws) は、テスト損失がモデルパラメータ数 ・データ量 ・計算量 のべき乗則で滑らかに下がる、という経験則。性能が「予測可能に」改善するため、大規模投資の根拠になりました。
- Chinchilla の知見は「固定の計算予算なら、モデルを大きくしすぎず と をバランスよく増やせ」。具体的な係数や最適比・創発の有無は議論があり、要最新確認です。
1. 事前学習:次トークン予測という自己教師あり学習
LLM の土台を作る工程が事前学習です。やることは LLMの全体像 で見た次トークン予測ただ一つ。大量の文章を流し込み、各位置で「次に来るトークン」を当てさせます。
正解は「実際に次に来たトークン」なので、人手のラベル付けは不要です。データ自身が答えを持っている——これを自己教師あり学習(self-supervised learning) と呼びます。これが、ウェブ規模の膨大なテキストをそのまま学習に使える理由です。
損失は交差エントロピー = 負の対数尤度 = 最尤
パラメータ のモデルが出す次トークン分布を とします。1 つの文書 に対する損失は、各位置の交差エントロピーの和です。
この右辺は、自己回帰モデル で見た対数尤度 にマイナスを付けただけです。つまり、
要するに:事前学習は「コーパスを最も高い確率で生成するパラメータを探す」最尤推定そのものです(数理は 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) 統計)。新しい原理ではなく、統計の王道を巨大な自己回帰モデルに適用しているだけ、と捉えると見通しが良くなります。
flowchart LR
Corpus["大規模テキストコーパス"] --> Tok["トークン列に変換"]
Tok --> Pred["各位置で次トークンを予測 p_θ(x_t given x_before)"]
Pred --> Loss["交差エントロピー損失 = 負の対数尤度"]
Loss --> Opt["勾配降下で θ を更新(最尤)"]
Opt -->|"全コーパスを反復"| Pred
2. causal LM と masked LM
「次トークン予測」は事前学習の一形態で、causal LM(自己回帰型) と呼ばれます。GPT 系がこれで、Transformer のデコーダ(マスク付き自己注意)を使い「過去だけ見て次を当てる」。生成に直結するのが特徴です。
対照的に masked LM(マスク言語モデル) は BERT 系で、文の一部を隠して前後両方の文脈から穴埋めさせます。双方向に文脈を見るので理解・分類タスクの表現づくりに強い一方、素直な逐次生成には向きません。
要するに:生成的な LLM の主流は causal LM(自己回帰)。「次を当てる」設定が、そのまま「文章を書く」能力になります。
3. スケーリング則:性能はべき乗則で予測できる
事前学習の規模を上げると性能はどう伸びるのか。Kaplan ら(2020)が見つけたのは、驚くほど滑らかなべき乗則(power law) でした。テスト損失 は、他の要因が十分なら、パラメータ数 ・データ量 ・計算量 のそれぞれに対してべき乗で下がります。
両対数グラフ( vs 等)に乗せると直線になり、これが何桁にもわたって成り立ちます。指数 や定数 などの具体的な値はモデル・データ・設定に依存し、移り変わるので要最新確認ですが、「規模を上げれば損失が予測可能に下がる」という形そのものが重要です。
flowchart TB
subgraph S["スケーリング則:3つの規模を上げると損失が下がる"]
N["パラメータ数 N を増やす"] --> L["テスト損失 L が べき乗則で低下"]
D["データ量 D を増やす"] --> L
C["計算量 C を増やす"] --> L
end
L -->|"両対数グラフで直線(要最新確認:指数・係数)"| Pred["性能を事前に予測できる"]
要するに:スケーリング則は「いくら投資すればどれだけ賢くなるか」をある程度事前に見積もれることを意味します。これが巨額の計算資源を投じる経営判断の根拠になりました。
⚠️ 注意:べき乗則は損失(次トークン予測の当てやすさ)についての経験則であって、下流タスクの有用性や安全性が同じ法則で伸びる保証はありません。また、適用範囲外(極端な領域)での外挿は危険です。
4. Chinchilla:計算予算をどう配分するか
現実には計算量 に予算上限があります。Transformer では計算量がおおよそ
で見積もれます(順伝播・逆伝播あわせて1パラメータ1トークンあたり約6演算)。同じ なら、 を大きくすれば は小さく、その逆も成り立つ—— と のトレードオフです。
Hoffmann ら(2022, 通称 Chinchilla)は、固定 のもとで損失 を最小化する配分を調べ、 と を概ね同じ割合でバランスよく増やすのが計算最適だと示しました。初期の大規模モデル(GPT-3 など)は**モデルが大きすぎてデータが足りない「学習不足(undertrained)」**であり、より小さいモデルをより多くのデータで学習した Chinchilla の方が同じ計算量で高性能でした。
要するに:「とにかくパラメータを増やす」が最適とは限らない。データと規模はセットで増やす。ただし最適なトークン対パラメータ比(よく「約20倍」と言われる)や係数は設定依存で議論が続いており、要最新確認です(データ枯渇や推論コストを考慮するとさらに変わります)。
5. 創発能力(emergent abilities)
スケーリングの面白い——そして論争的な——側面が創発能力です。Wei ら(2022)は、ある種のタスク(多段の算術や推論など)で、規模が小さいうちはほぼ偶然並みなのに、ある規模を超えると急に性能が立ち上がる、連続的でない「創発」が見られると報告しました。
一方で「創発は測り方の産物(mirage)」という批判(Schaeffer ら, 2023)もあります。完全一致のような不連続な指標だと急に見えるが、部分点を与える滑らかな指標で測れば改善は連続的だ、という主張です。
要するに:規模で質的に新しい能力が出るのか、それとも指標の見え方の問題なのかは決着しておらず、要最新確認の領域です。「大きくすれば魔法のように何でもできる」と素朴に信じるのは危険です。
⚠️ よくある誤解・要最新確認
- 「スケーリング則の係数は普遍の定数」ではない。指数 や は設定・データ・アーキテクチャ依存で、研究ごとに更新されます(要最新確認)。
- 「大きいモデルほど常に良い」ではない。Chinchilla の通り、データが伴わない巨大モデルは学習不足で非効率。 と はセットで考えます。
- 「損失が下がる=有用・安全になる」ではない。事前学習の損失は次トークンの当てやすさにすぎず、指示追従・無害性は別途アラインメント(アラインメント)が要ります。
- 「創発能力は確立した事実」ではない。指標依存だとする反論があり、未決着(要最新確認)。
- データの枯渇・質:高品質テキストの総量には限りがあり、データ側がボトルネックになりうる論点も活発です(要最新確認)。
対応するシミュレーション
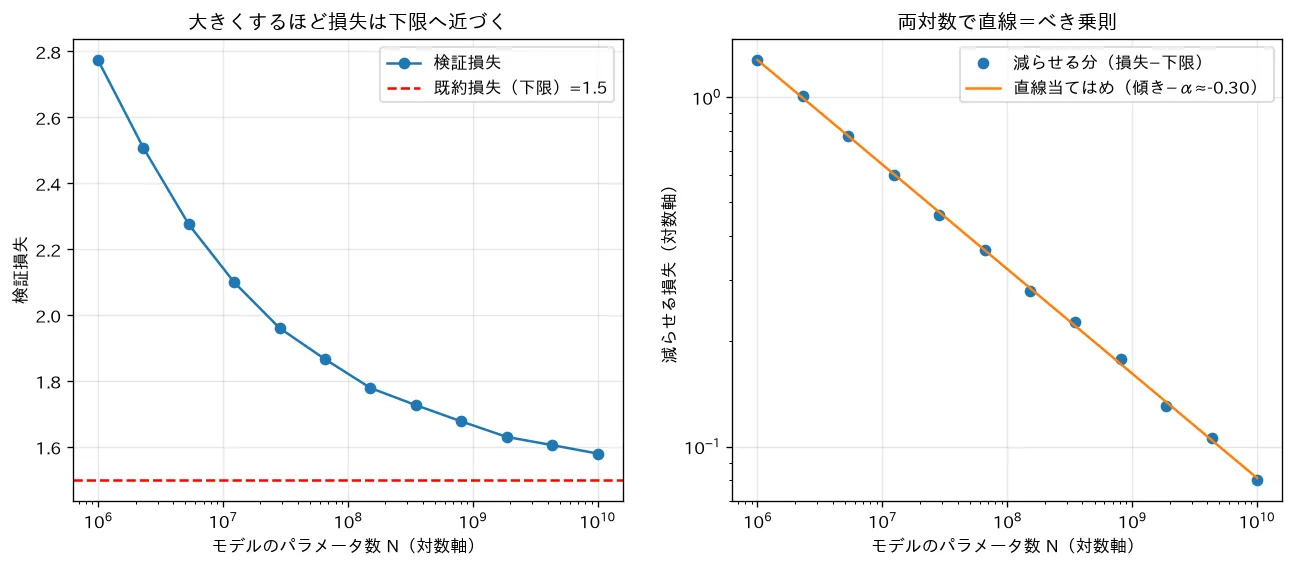
simulations/scaling_laws.py:べき乗則 に従う合成の損失データで、モデルサイズ を増やすと損失が既約損失 (下限)へ漸近すること、そして「減らせる分 」を両対数でとると傾き の直線になることを可視化します。データから指数 をきれいに復元でき、べき乗則が小さな実験から大規模性能を外挿できる根拠になることを示します。最適なモデル/データ配分の議論が Chinchilla 則(具体値は要最新確認)。
関連ノート
- 大規模言語モデル 目次
- LLMの全体像
- ファインチューニング(事前学習の次の工程)
- 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論)(統計・最尤推定の土台)
- ハイパーパラメータ最適化(計算予算と探索)
- 機械学習テキスト 全体目次