📊 対象級:準1級 ・ 1級 | 重要度:B(標準)
要点(BLUF)
ベイズ推定の答えは事後分布 ですが、その正規化定数 が高次元では解析的に解けません。そこで「正規化定数を知らなくても事後分布から標本を取る」工夫が MCMC(マルコフ連鎖モンテカルロ) です。目標の事後分布 を定常分布に持つマルコフ連鎖を作り、それを長く回して出てきた点の列を からの標本とみなします。
これがメトロポリス・ヘイスティングス法の受容確率です。要するに「提案 をこの確率で受け入れる連鎖を作ると、その定常分布がちょうど になる」。核心は が比 でしか現れないので、厄介な正規化定数が約分で消えることです。準1級では概念とこの受容確率の計算、1級では「受容確率が詳細釣り合いを満たす→ が定常分布になる」導出と収束理論が問われます。
1. なぜ MCMC が要るのか(正規化定数の壁)
ベイズの定理(ベイズの定理)から、事後分布は
と書けます(事前分布・事後分布・ベイズ更新)。分子(尤度×事前)は を代入すればいつでも計算できます。問題は分母の正規化定数(周辺尤度)
です。これは の全空間にわたる積分で、要するに「分子を全部足したらいくつになるか」という規格化の係数です。
1.1 何が困るのか
ベイズ推定で実際に欲しいのは事後分布そのものより、そこからの期待値です。例えば事後平均(ベイズ推定・MAP推定)
を求めるには、分子も分母も積分が要ります。共役な組み合わせ(共役事前分布)なら も期待値も手計算で出ますが、現実のモデルはほとんど非共役です。さらに が高次元(パラメータが何十個もある階層モデルなど)になると、 の積分は次元の呪いで数値積分も歯が立ちません。
1.2 MCMC の発想
そこで発想を変えます。「 を計算する」のではなく、「 から大量に標本 を取り、期待値を標本平均で近似する」。
これは普通のモンテカルロ積分です。問題は「正規化されていない事後 しか分からないのに、どうやってそこから標本を取るか」。その標本生成を、 を定常分布とするマルコフ連鎖で実現するのが MCMC です。連鎖を回して得た点の列が、約束された性質(後述のエルゴード性)のもとで からの標本になります。
核心の一言:MCMC は を一切計算しません。後で見るように、受容確率に が比でしか現れないため、 は分子分母で約分されて消えます。これが「正規化定数が解けなくてもベイズ計算できる」理由です。
2. マルコフ連鎖の基礎(最小限)
MCMC を理解するのに必要なマルコフ連鎖の道具だけ整理します。連鎖そのものの一般論は 確率過程(マルコフ連鎖・ポアソン過程) に譲り、ここでは「目標分布を定常分布にする」ために要る概念に絞ります。
2.1 マルコフ性と推移核
マルコフ連鎖は「次の状態が、現在の状態だけで決まり、過去には依存しない」確率過程です。
要するに「1個前の状態さえ分かれば、それより昔は忘れてよい」。遷移のルールを推移核(遷移核) で表します(離散なら推移確率行列 、連続なら推移密度 )。
2.2 定常分布
分布 が推移核 の定常分布であるとは、 から出発した1ステップ後の分布がまた に戻ることです。
要するに「 にいったん落ち着いたら、連鎖を進めても分布が のまま動かない」。MCMC の目標は、欲しい事後分布 をこの定常分布に持つような推移核 を人工的に設計することです。
2.3 連鎖が「ちゃんと使える」ための条件
定常分布を持つだけでなく、どこから始めても定常分布に近づき、標本平均が真の期待値に収束することが要ります。そのための条件が以下です。
| 条件 | 意味(要するに) |
|---|---|
| 既約性(irreducibility) | どの状態からどの状態へも有限ステップで到達できる。状態空間に「行けない孤島」がない |
| 非周期性(aperiodicity) | 周期的にしか戻れない、ということがない。決まったリズムで循環しない |
| エルゴード性(ergodicity) | 既約かつ非周期 → 初期値によらず分布が一意の定常分布に収束する |
エルゴード性が成り立つと、エルゴード定理により時間平均が空間平均(期待値)に一致します。
要するに「1本の連鎖を長く回した平均が、定常分布での期待値に収束する」。これが「連鎖の出力を の標本として使ってよい」理論的な根拠です。
2.4 詳細釣り合い(detailed balance)
定常分布の式 を直接設計するのは難しい(全状態の積分が絡む大域的な条件)です。そこで、もっと強くて局所的で扱いやすい条件を使います。それが**詳細釣り合い(可逆性)**です。
要するに「 から への正味の流れと、 から への流れが釣り合っている」。状態間を行き来する確率の流れがどのペアでも左右対称、というイメージです。詳細釣り合いを満たす連鎖を**可逆(reversible)**と呼びます。
重要:詳細釣り合いは定常性の十分条件です(必要ではない)。詳細釣り合いさえ示せば、 を直接確かめなくても が定常分布だと保証されます。証明は次節。
3. 詳細釣り合い → 定常分布の導出(1級の核心)
詳細釣り合いを満たせば が定常分布になることを示します。ここは1級で論述させられる部分なので、省略せず追います。
仮定: がすべての で成り立つ。
示したいこと:(つまり )。
両辺の左側を出発点に、詳細釣り合いで被積分関数を入れ替えます。
最後の鍵は「 から出てどこかへ行く確率の合計は1」という、推移核そのものの性質 です。これで 、すなわち が定常分布だと示せました。
要するに:詳細釣り合い(局所的な流れの対称性)を「全部の について足す(積分する)」と、右辺は遷移確率の総和が1になって がそのまま残る。だからペアごとの釣り合いを設計するだけで、大域的な定常性が自動的に手に入る。これが MCMC の設計戦略の土台です。
あとは「目標 について詳細釣り合いを満たす推移核を、実際にどう作るか」。それがメトロポリス・ヘイスティングス法です。
4. メトロポリス・ヘイスティングス法
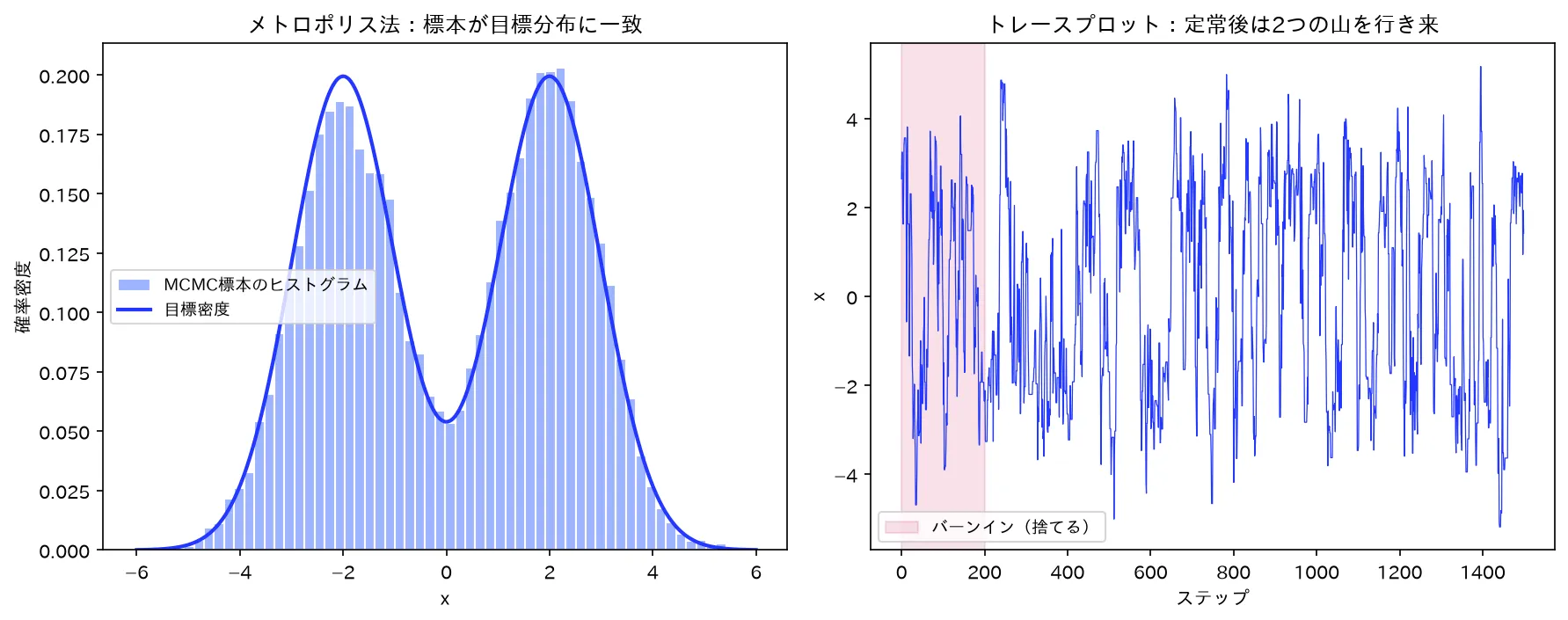
図は simulations/mcmc_metropolis.py で生成。
4.1 アルゴリズム
現在地 から、次の手順で次の点 を決めます。
- 提案:提案分布(遷移分布) から候補 を1つ生成する(例:現在地中心の正規分布 でふらつかせる)。
- 受容確率の計算:
- 採否の決定: を引き、 なら受容して 、そうでなければ棄却して (その場にとどまる)。
- これを繰り返し、得られた点列 を からの標本とみなす。
要するに「当てずっぽうに次の点を提案し、事後密度が上がるなら基本受け入れ、下がるならその比に応じた確率で受け入れる」。下がる方向も時々受け入れるからこそ、山頂に貼り付かず分布全体をうろつけます。
flowchart TD
A["現在地 θ"] --> B["提案分布 q から候補 θ' を生成"]
B --> C["受容確率を計算<br/>α = min(1, π(θ')q(θ|θ') / π(θ)q(θ'|θ))"]
C --> D["一様乱数 u ~ U(0,1) を引く"]
D --> E{"u ≤ α ?"}
E -- "Yes(受容)" --> F["θ_next = θ'(移動)"]
E -- "No(棄却)" --> G["θ_next = θ(その場にとどまる)"]
F --> H["θ_next を標本に記録"]
G --> H
H --> A
4.2 正規化定数が消える(核心)
受容確率の は比 でしか現れません。事後分布 ( は事前、 は正規化定数)を代入すると
が分子分母で約分されて消えました。 つまり受容確率は「尤度×事前」(計算できる分子)だけで決まり、解けない正規化定数 を一切使いません。
要するに「 が分からなくてもベイズ計算ができる、最大の理由がこの約分」。第1節で立てた壁を、ここで突破しています。
4.3 対称提案 → メトロポリス法
提案分布が対称 (正規分布 や一様な小ステップなど、行きと帰りの提案確率が等しい)なら、 の比が1になって受容確率は
これが元祖メトロポリス法です。要するに「提案が対称なら、受容確率は事後密度の比だけ」。(密度が上がる)なら比が1以上で 、必ず受容。下がるなら比そのものの確率で受容。メトロポリス・ヘイスティングス法は、これを非対称な提案でも使えるよう の補正項を入れて一般化したものです。
準1級の頻出計算:「現在 、提案 のとき、対称提案での受容確率を求めよ」。 は正規化前の値(尤度×事前)でよいので、 を計算して を取るだけです。
5. 受容確率が詳細釣り合いを満たす導出(1級の核心)
「なぜこの受容確率なら が定常分布になるのか」を示します。第3節で「詳細釣り合いを満たせば は定常分布」と証明済みなので、ここでは MH の推移核が について詳細釣り合いを満たすことを示せば十分です。
MH の推移核( のとき、実際に へ移る密度)は「提案する確率 × 受容する確率」
です。これが詳細釣り合い を満たすことを示します。左辺は
ここで の中の分母 を外の係数と組ませると、一般公式 ()が使えます。、 として
この式は と を入れ替えても同じ( は対称:)です。 と を全部入れ替えた右辺を計算すると
両者ともに になり、一致します。
よって MH の推移核は について詳細釣り合いを満たし、第3節の結果から が定常分布になります。
要するに:受容確率を という形に取った瞬間、 が対称な量 に化ける。 が左右対称だから詳細釣り合いが自動的に成り立つ。この「 にすると対称になる」仕掛けこそ、受容確率があの形である理由です。なお棄却して にとどまる確率は両辺に同じだけ寄与するので、上の の議論で十分です。
エルゴード性(既約・非周期)は、提案分布 が状態空間全体に正の確率を割り振っていれば(例:全空間で正の正規分布の提案)満たされます。詳細釣り合い(定常性)+エルゴード性で、連鎖の標本平均が事後期待値に収束することが保証されます。
6. ギブスサンプリング
ギブスサンプリングは、パラメータが多次元 のときに使える MCMC の特別な形です。発想は「1成分ずつ、他を固定したときの条件付き分布から順に引く」。
各ステップで、 以外を今の値に固定した完全条件付き分布(full conditional)
から を1つサンプリングし、これを と順に回して1サイクルとします。たとえば2次元なら
要するに「多次元の同時分布を直接扱う代わりに、1変数ずつの条件付き分布に分解して順番にサンプリングする」。
ギブスの利点と前提
- 受容判定が不要:完全条件付き分布から直接サンプリングできるなら、提案はつねに受容されます(受容確率がつねに1になる MH の特殊ケースと見なせる)。棄却がない分、効率がよいことが多い。
- 前提:各 の完全条件付き分布が既知の分布で、そこから直接サンプリングできること。共役な階層モデル(共役事前分布)では完全条件付き分布が標準分布(正規・ガンマ・ベータなど)になり、ギブスが使えます。
- 条件付き分布から直接引けない成分があれば、その成分だけ MH を使う(メトロポリス内ギブス)。
要するに:ギブスは「条件付き分布が綺麗に出る問題」専用の MH。問題の構造(共役性)に乗れるなら受容判定なしで回せる分お得、というのが位置づけです。
7. 収束診断
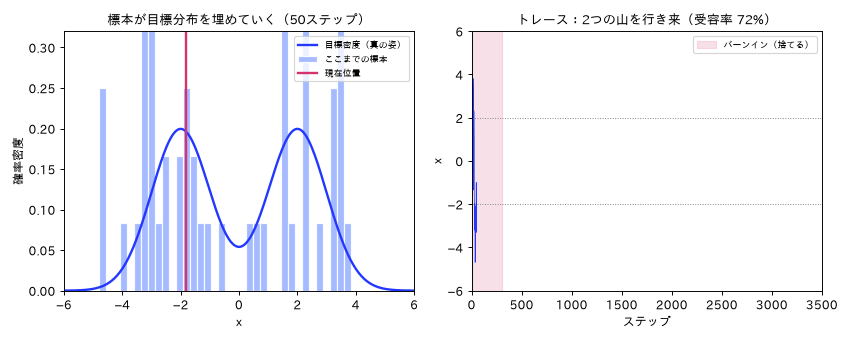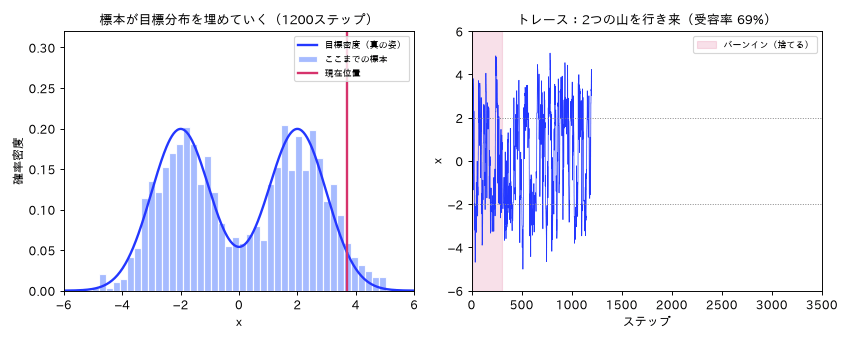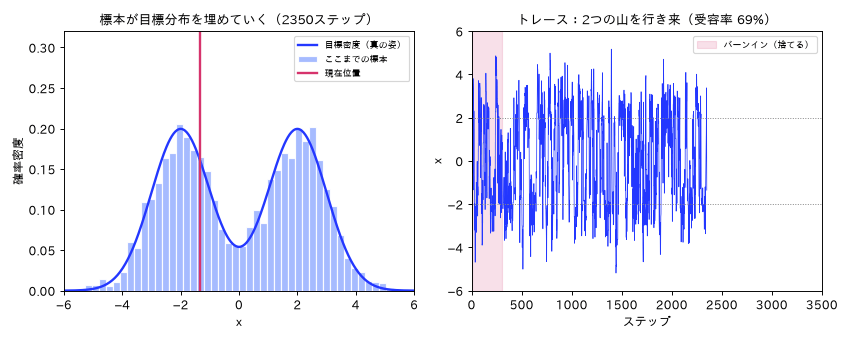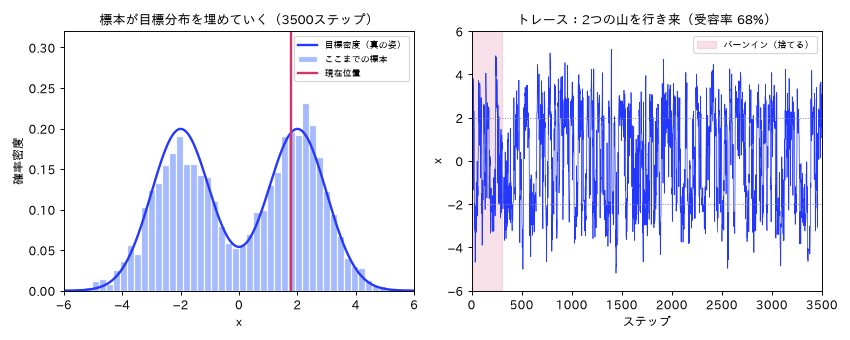
図(アニメ)は simulations/mcmc_metropolis_anim.py で生成。連鎖が歩きながら標本のヒストグラムが目標分布の形に埋まり、バーンインの助走後に2つの山を往復して定常状態に入る様子を動きで示す。
MCMC の出力は理論上は無限ステップで に収束しますが、有限回では「まだ定常に達していない初期」や「強い相関で実質的な情報量が少ない」問題があります。これを点検するのが収束診断です。
| 診断 | 何を見るか(要するに) |
|---|---|
| バーンイン(burn-in) | 初期の数百〜数千ステップは初期値の影響が残るので捨てる。定常に落ち着く前の助走区間 |
| トレースプロット | サンプル値を時間軸で折れ線にする。水平な帯状にばらつけば収束、ドリフトや張り付きがあれば未収束 |
| 自己相関(autocorrelation) | 連続する標本は相関する(前の点から少しずらすだけだから)。相関が強いほど「同じような点」が並び、実質の情報が少ない |
| 有効サンプルサイズ(ESS) | 自己相関を考慮した「実質の独立標本数」。 個取っても相関が強いと ESS は より大幅に小さい |
| Gelman–Rubin() | 初期値を変えた複数チェーンを回し、チェーン間とチェーン内の分散を比較。 なら収束、 から大きく外れると未収束 |
要するに「標本が本当に を代表しているか(初期の影響が抜けたか・相関で痩せていないか)を確かめる作業」。有効サンプルサイズの直観は
( はラグ の自己相関)で、相関 が大きいほど分母が膨らみ ESS が減ります。要するに「相関が強いほど、たくさん取っても独立標本としては少ししか得していない」。
8. 引っかけ・頻出論点
- ⚠️ MCMC は正規化定数 を計算しない:受容確率に が比で入るので が約分で消える。「事後分布が解析的に出せないから MCMC」の核心はここ。「 を数値積分する手法」と勘違いしない。
- ⚠️ 対称提案かどうかで受容確率の形が変わる:対称(メトロポリス)なら 。非対称なら の補正項 が必要(メトロポリス・ヘイスティングス)。提案が対称と決めつけて の項を落とすミスが頻出。
- ⚠️ 詳細釣り合いは定常性の十分条件であって必要条件ではない:詳細釣り合いを満たせば定常だが、定常な連鎖が必ず詳細釣り合いを満たすわけではない(可逆でない MCMC も存在する)。
- ⚠️ 棄却されても標本は記録する:MH で棄却したら次の点は現在地と同じ値になる。これも1つの標本として数える(その場にとどまる時間が事後確率の高さを表す)。棄却=「何も記録しない」ではない。
- ⚠️ 収束=バーンイン後:バーンイン区間のサンプルは初期値依存なので期待値計算から除く。自己相関が強い場合はステップ幅(提案分布の分散)の調整が要る。
- ⚠️ ギブスは受容判定不要だが前提が要る:完全条件付き分布から直接サンプリングできる場合に限る。これができないと普通の MH に戻る。
試験での問われ方(級ごとの差)
MCMC は準1級・1級の出題範囲ですが、毎回必ず出るわけではありません(出題範囲・配点は改訂されうるため要最新確認)。級で問われる深さが明確に違います。
準1級レベル
ここで問われるのは「概念と手順、受容確率の計算」。なぜ MCMC が要るか(正規化定数の壁)を説明でき、メトロポリス法の手順をたどれ、与えられた の値から受容確率を計算できるか。
- 「事後分布の正規化定数が解析的に求まらないとき MCMC を使う」理由を選ぶ。
- メトロポリス法の受容確率を実際に計算する。 は正規化前(尤度×事前)でよく、 を計算する(対称提案)。
- バーンイン・自己相関・トレースプロット・収束診断の用語と役割の理解。ギブスサンプリングが「条件付き分布から逐次サンプリングする手法」だという定性的理解。
1級レベル
ここで問われるのは「理論と導出」。詳細釣り合いの定義から が定常分布になることを導き、MH の受容確率がなぜその形かを詳細釣り合いから説明できるか。収束理論(エルゴード性)まで。
- 詳細釣り合い → 定常分布の導出(第3節:両辺を積分し を使う)。
- MH の受容確率が詳細釣り合いを満たすことの導出(第5節: と の対称性)。
- 既約性・非周期性・エルゴード性と、エルゴード定理(時間平均→空間平均)による標本平均の収束の保証。マルコフ連鎖一般の性質は 確率過程(マルコフ連鎖・ポアソン過程) が前提。
最尤法・尤度の扱いは 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論)、事後分布の作り方は 事前分布・事後分布・ベイズ更新 が前提です。
よくある疑問(Q&A)
Q1. なぜ「正規化定数が解けない」ことが、わざわざマルコフ連鎖を作る理由になるのですか?
正規化定数 が解析的に解けず、高次元では数値積分も無理だからです。普通の棄却サンプリングや逆変換法は分布の規格化された形を要求しますが、MCMC は比 しか使わないので が約分で消え、規格化なしで標本が取れます。「 を求めずに事後から標本を取る」唯一現実的な道がマルコフ連鎖を回すことだ、というのが理由です。
Q2. 受容確率が下がる方向(事後密度が低い候補)も時々受け入れるのはなぜですか? 山頂だけ取れば十分では?
山頂(MAP)だけ取ると事後分布の形が再現できないからです。MCMC が欲しいのは1点ではなく分布全体(から期待値や信用区間を計算する、ベイズ推定・MAP推定)。下がる方向も比 の確率で受け入れるからこそ、密度の高いところに長く、低いところに短く滞在し、滞在時間の割合が事後確率に比例します。下がる方向を全く受け入れないと山頂に貼り付いて、分布の裾を一切サンプリングできません。
Q3. メトロポリス法とメトロポリス・ヘイスティングス法は何が違うのですか?
提案分布 が対称か非対称かだけの違いです。メトロポリス法は対称提案(、正規分布での提案など)専用で、受容確率は 。メトロポリス・ヘイスティングス法はこれを非対称提案でも正しく動くよう一般化し、補正項 を掛けます。対称なら補正項が1になり MH がメトロポリスに退化します。つまりメトロポリスは MH の特殊ケースです。
Q4. 棄却された場合、その回は標本としてどう扱いますか?
棄却したら次の状態は現在地と同じ値になり、それを1つの標本として記録します。「棄却=記録なし」ではありません。同じ点が連続して記録されるのは、その点の事後確率が高く滞在が長いことの表れで、これがあるからこそ滞在時間が事後確率に比例します。これを誤解して棄却時に何も記録しないと、滞在時間の重み付けが壊れて事後分布が歪みます。
Q5. ギブスサンプリングはメトロポリス法と全く別物ですか?
別物ではなく、ギブスは受容確率がつねに1になる MH の特殊ケースと見なせます。完全条件付き分布からそのまま引くので「提案が必ず受容される」状況に相当します。だから受容判定が要りません。ただし使える条件が厳しく、各成分の完全条件付き分布が既知でサンプリング可能(共役モデルなど)でなければなりません。引けない成分があればその成分だけ通常の MH を使う「メトロポリス内ギブス」になります。
まとめ
- ベイズ計算の壁は正規化定数 が高次元で解けないこと。MCMC は を計算せず、 を定常分布に持つマルコフ連鎖を回して事後標本を得る。
- 設計戦略は詳細釣り合い:。これを満たせば が定常分布(両辺を積分し より )。
- メトロポリス・ヘイスティングス法の受容確率 。 が比で入るので が約分で消えるのが核心。対称提案なら (メトロポリス法)。
- 受容確率がこの形だと となり、 の対称性から詳細釣り合いが成り立つ。
- ギブスサンプリングは完全条件付き分布から逐次サンプリング(受容判定不要だが条件付き分布が既知である前提)。収束診断はバーンイン・トレースプロット・自己相関・有効サンプルサイズ・。
- 準1級は概念と受容確率の計算、1級は詳細釣り合い→定常分布・受容確率の導出・収束理論。
関連ノート
- 事前分布・事後分布・ベイズ更新 MCMC が標本を取る対象である事後分布の作り方
- 共役事前分布 事後が解析的に出る場合(MCMC が不要な恵まれたケース/ギブスの前提)
- ベイズ推定・MAP推定 MCMC 標本から事後平均・信用区間を計算する出口
- ベイズの定理 事後 ∝ 尤度 × 事前。正規化定数 の出どころ
- 確率過程(マルコフ連鎖・ポアソン過程) マルコフ連鎖の本体(推移核・既約性・エルゴード性)の一般論
- 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) 受容確率に入る尤度 の扱い
- ベイズ統計・実験計画(Phase 7 目次) ベイズ統計・実験計画ドメインの全体地図