📊 対象級:準1級 ・ 1級 | 重要度:B(標準)
要点(BLUF)
生存時間解析は「あるイベント(死亡・故障・解約)が起きるまでの時間 」を扱う分野です。普通の解析と決定的に違うのは、観察が終わっても多くの人でイベントがまだ起きていない、という**打ち切り(censoring)**が必ず混じる点。打ち切りデータは「少なくとも今まで生きた」という情報を持つので、捨てると推定が偏ります。
中心になる量は3つで、すべて互いに変換できます。
要するに「生存関数 ・ハザード ・累積ハザード はどれか1つ決まれば残り2つも決まる」。打ち切りを扱える推定がカプラン・マイヤー法、2群比較がログランク検定、共変量の効果をハザード比で測るのがCox比例ハザードモデルです。準1級ではKM法の計算とハザード比の解釈、1級では部分尤度の構成と比例ハザード仮定の検証まで問われます。
1. なぜ普通の解析が使えないのか — 打ち切り
生存時間 は「イベントが起きるまでの時間」です。死亡までの日数、機械が故障するまでの稼働時間、契約解約までの月数など、応答が「時間」になっている点が特徴です。これだけなら指数分布やガンマ分布(指数分布・ガンマ分布・ベータ分布)の当てはめで済みそうですが、現実のデータには必ず打ち切りが混じります。
**打ち切り(censoring)とは、その個体のイベント発生時刻を正確には観測できなかった状態を指します。中心になるのは右側打ち切り(right censoring)**で、観察を打ち切った時点でまだイベントが起きていない場合です。原因は主に2つ。
- 観察期間の終了:研究期間が終わった時点で、まだ生存している(イベント未発生)。
- 脱落(loss to follow-up):転院・連絡不能などで途中から追跡できなくなった。
打ち切られた個体について分かるのは「少なくとも時刻 まではイベントが起きていない」、つまり という情報です。
要するに「打ち切りは『 がいくつか分からない』だけで、『 が より大きい』という情報は持っている」。ここが欠測(データそのものが無い)との決定的な違いです。
なぜ打ち切りを捨ててはいけないか
「打ち切りデータを除いて、イベントが観測できた人だけで平均生存時間を出せばいい」と思いがちですが、これは強い下方バイアスを生みます。打ち切られるのは「長く生きている(まだイベントが起きていない)」個体が多いので、それらを除くと短命な個体だけが残り、生存時間を過小評価してしまうからです。
flowchart TB D["生存時間データ T"] --> E1["イベント観測<br/>T が正確に分かる"] D --> C1["右側打ち切り<br/>T > c しか分からない"] C1 --> R1["観察終了"] C1 --> R2["脱落"] E1 --> KM["カプラン・マイヤー法<br/>打ち切りを risk set の減少で扱う"] C1 --> KM KM --> CMP["2群比較 → ログランク検定"] KM --> COX["共変量 → Cox 比例ハザードモデル"]
要するに「打ち切りを正しく情報として使う枠組みが生存時間解析であり、だから専用の手法(KM法・ログランク・Cox)が要る」ということです。
2. 生存時間を記述する3つの関数
生存時間 (連続・非負の確率変数)を、互いに同値な3つの関数で表します。どれか1つで分布が完全に決まります。
2.1 生存関数
要するに「時刻 を超えてまだイベントが起きていない確率」。 は累積分布関数、 は密度です。 で単調非増加、 で に近づきます。
2.2 ハザード関数 (瞬間死亡率)
要するに「時刻 まで生き延びた個体が、その直後の一瞬でイベントを起こす『率(rate)』」。条件付き確率を で割っているので、これは確率ではなく単位時間あたりの率で、 を超えてもよい量です(ここが超頻出の引っかけ)。
このハザードを密度と生存関数で書き直すのが基本式です。条件付き確率の分子は 、条件は なので、
要するに「ハザード = 密度 ÷ 生存確率」。同じ「いま死ぬ密度 」でも、まだ生き残っている人が少なければ( が小さい)ハザードは高くなる、という条件付きの量です。
2.3 累積ハザード関数
要するに「時刻 から までに浴びたハザードの総量」。単調非減少で 、 で に発散します(最終的には全員イベントを起こすため)。
3. 中心となる関係式 の導出
3つの関数を結ぶ最重要の恒等式が
です。これは1級で導出ごと問われます。自明で済ませず順を追って導きます。
ステップ1:ハザードを の対数微分で書く。 密度は ( かつ なので )です。これを に代入すると
要するに「ハザードは生存関数の対数の傾き(の符号反転)」。 がどれだけ速く落ちているか、がそのままハザードです。
ステップ2:両辺を から まで積分する。
左辺は定義より 。 なので 。よって
要するに「累積ハザード = マイナス対数生存関数」。これは という形でもよく登場します。
ステップ3:指数を取って解く。
導出完了です。この鎖により、 がすべて行き来できます()。
なぜこの式が嬉しいか:後で出るカプラン・マイヤー法は を直接推定し、ハザードをモデル化するCox回帰は を扱います。 があるおかげで、片方を推定すればもう片方に変換でき、「 の世界」と「 の世界」を自由に往復できます。
4. パラメトリックな例:指数分布とワイブル分布
ハザードの形を関数で仮定するのがパラメトリック生存モデルです。代表が2つあります。
4.1 指数分布 = 定数ハザード(無記憶性)
ハザードが定数 (時間によらない)と置くと、、。これはちょうど指数分布です(指数分布・ガンマ分布・ベータ分布)。
要するに「ハザードが一定 = 指数分布」。「今まで何時間生きたか」がこの先の故障率に影響しない、という**無記憶性(memoryless)**の言い換えでもあります。新品でも使い古しでも次の一瞬で壊れる率が同じ、という非現実的に単純なモデルです。ポアソン過程(ポアソン分布)の到着間隔がこれに当たります。
4.2 ワイブル分布 = 単調なハザード
ハザードを ()と置くとワイブル分布になります。累積ハザードは 、生存関数は 。
要するに「形状パラメータ でハザードの増減を切り替えられる」分布です。
| 形状 | ハザードの挙動 | 解釈 |
|---|---|---|
| 単調増加 | 摩耗・老化(時間とともに壊れやすく) | |
| 一定 | 指数分布に一致(無記憶) | |
| 単調減少 | 初期故障(最初に壊れやすく、生き残れば安定) |
で指数分布に退化することからも、ワイブルは指数分布の一般化だと分かります。
5. カプラン・マイヤー推定量(積極限推定量)
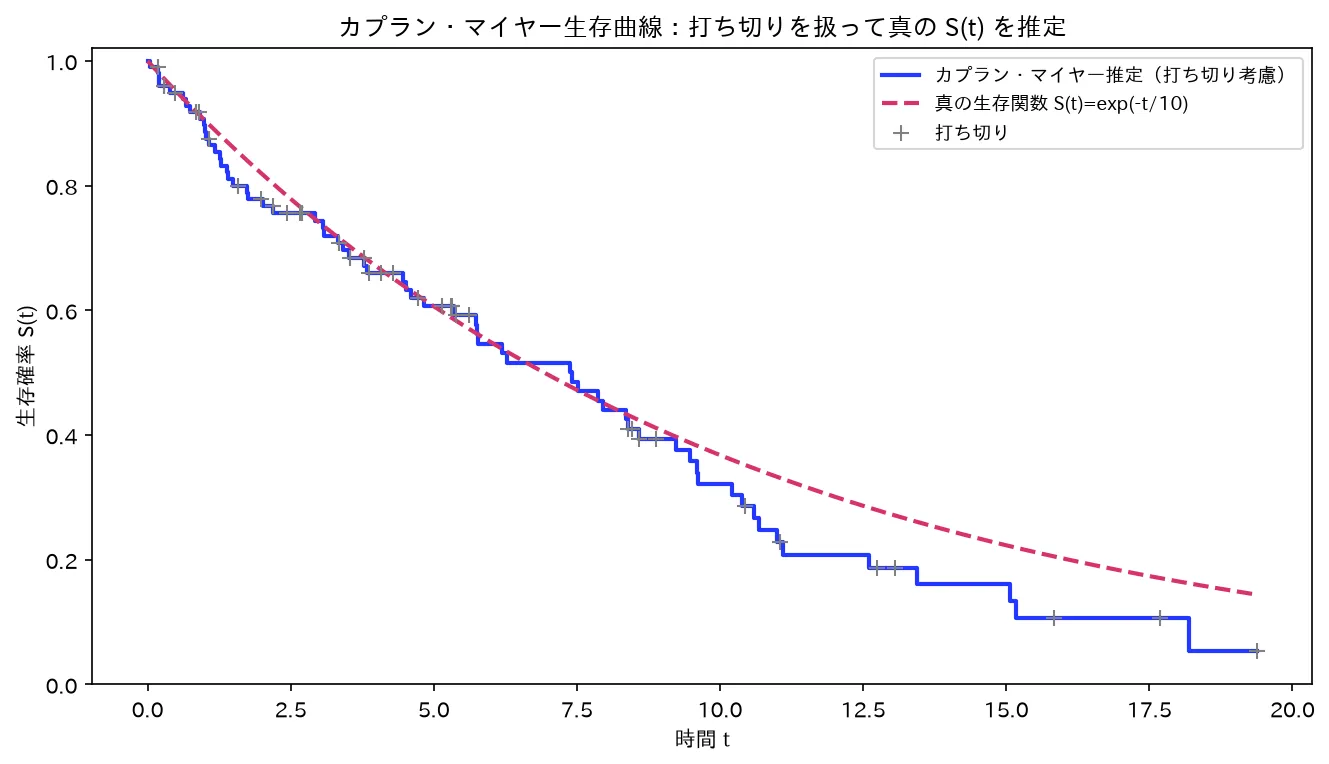
打ち切り(灰の+)を含むデータから、カプラン・マイヤーが階段状に生存関数を推定し、真の S(t)=exp(-t/10) に一致する。図は simulations/kaplan_meier_keijou.py で生成。
分布形を仮定せず、打ち切りを含むデータから をノンパラメトリックに推定するのがカプラン・マイヤー(Kaplan-Meier)推定量、別名**積極限推定量(product-limit estimator)**です。準1級では手計算が問われます。
イベントが起きた相異なる時刻を とし、各時刻で
- :時刻 でのイベント数(死亡数)
- :時刻 の直前でまだイベントも打ち切りも起きていない個体数(リスク集合 risk set の大きさ)
と定義します。推定量は
要するに「各イベント時刻での『その瞬間を生き延びる条件付き確率』 を、 までかけ合わせたもの」。 まで生きるとは「各関門をすべて通過する」ことなので、条件付き生存確率の積になります。
5.1 なぜ打ち切りを扱えるのか(核心)
KM法の肝は、打ち切りをリスク集合 の減少だけで処理する点です。
時刻 で生き延びる条件付き確率は「その時点でリスクにさらされている 人のうち 人がイベントを起こす」割合の補数 です。ここで** より前に打ち切られた個体は、もう に含まれていません**(リスク集合から外れている)。つまり打ち切りは「そこから先のリスク計算に参加しなくなる」という形で自然に織り込まれ、 の分母 を減らすだけで済みます。
要するに「打ち切りはイベントとしてカウントせず(分子 に入れない)、ただリスク集合から退場させる(分母 を減らす)」。これが「 という情報を捨てずに使う」ことの具体的な実装です。打ち切られた個体も、退場するまではちゃんとリスク集合に居続けて分母に貢献している点が重要です。
数理的には、 は打ち切りを含む尤度(イベントは 、打ち切りは で寄与)を最大化するノンパラメトリック最尤推定量になっていることが示せます(1級の論点。最尤法は 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論))。
5.2 階段関数になる
はイベントが起きた時刻でだけ下に段差ができ、その間は水平な階段関数です。打ち切りだけが起きた時刻では なので となり、段差は生じません(曲線は下がらない)。慣例として打ち切り時刻はグラフ上に「+」印で示します。
5.3 計算例
5人の患者、観測値(†は打ち切り)が のとき:
| 時刻 | リスク集合 | イベント | 打ち切り | ||
|---|---|---|---|---|---|
| 2 | 5 | 1 | 0 | ||
| 3 | 4 | 0 | 1 | (段差なし) | |
| 5 | 3 | 2 | 0 | ||
| 8 | 1 | 0 | 1 | (段差なし) |
要するに「 の打ち切りは段差を作らないが、 のリスク集合を から に減らしている」。この『打ち切りが分母に効く』のを正しく追えるかが準1級の典型問題です。
6. ログランク検定(2群の生存曲線の比較)
「治療群と対照群で生存に差があるか」を、KM曲線が描けたうえで検定するのが**ログランク検定(log-rank test)**です。生存曲線まるごとを比べるノンパラメトリックな検定で、ノンパラ検定(ノンパラメトリック検定(符号・順位和・Wilcoxon))の生存版に当たります。
6.1 各イベント時刻で 表を作る
イベントが起きた各時刻 で、群 ・群 について次の分割表を作ります。
| イベント | 生存 | リスク集合 | |
|---|---|---|---|
| 群1 | |||
| 群2 | |||
| 合計 |
「2群で差がない()」が帰無仮説です。このとき、 人から 人がイベントを起こすなら、群1から出るイベント数 は超幾何分布に従います。その期待値と分散は
要するに「帰無仮説のもとで群1に期待されるイベント数は、群1のリスク人数の比率 に全イベント を割り振った値」。差がなければ、イベントはリスク人数に比例して両群に分配されるはずだ、という考え方です。
6.2 全時刻で足し合わせてカイ二乗統計量に
各時刻の「観測 期待」を全イベント時刻で合計し、分散の合計で正規化します。
要するに「群1の総観測死亡数 と総期待死亡数 のズレを、分散で標準化した量」で、帰無仮説のもとで自由度1のカイ二乗分布に近づきます。 が より大きく外れるほど「2群で生存が違う」証拠になります。
⚠️ 簡便版として (=群、ピアソン型)も使われますが、これは近似で、正式なログランク統計量は上の超幾何分布の分散 で割る形です。級によってどちらの式を要求するか確認してください。
7. Cox 比例ハザードモデル(半パラメトリック)
共変量 (年齢・治療の有無・用量など)が生存にどう効くかを、ハザードを通してモデル化するのがCox比例ハザードモデルです。生存時間解析で最もよく使われ、準1級・1級ともに頻出です。
7.1 モデルの定義
ここで は共変量がすべて のときのハザードで**ベースラインハザード(baseline hazard)**と呼びます。要するに「ハザードを『時間だけの部分 』と『共変量だけの部分 』の掛け算に分ける」モデルです。
決定的なのは、時間に依存する を関数形を一切仮定せず未知のまま残す点です。(共変量の効果)はパラメトリックに、 はノンパラメトリックに扱うので**半パラメトリック(semi-parametric)**と呼ばれます。一般化線形モデル(一般化線形モデル(ロジスティック・ポアソン回帰))が分布を完全に決めるのと対照的に、Coxは分布形を決め打ちしないのが強みです。
7.2 比例ハザード仮定とハザード比
2個体 のハザードの比を取ると、共通の が約分されて消えます。
要するに「2個体のハザード比は時刻 を含まない(時間によらず一定)」。これが**比例ハザード仮定(proportional hazards assumption)**の意味です。「治療群のハザードは対照群の常に 倍」のように、比が時間を通じて一定だと仮定しています。
共変量 を1単位増やしたときのハザード比は
要するに「 が、その共変量を1単位上げたときにハザードが何倍になるか(ハザード比)」。(HR)なら危険を増やす因子、(HR)なら保護的な因子です。(HR)なら効果なし。準1級ではこのハザード比の解釈が中心です。
7.3 部分尤度による の推定(1級)
問題は「 が未知関数なのに、どうやって だけ推定するか」です。Coxの答えが**部分尤度(partial likelihood)**です。
イベントが起きた各時刻 で「リスク集合 にいた個体のうち、なぜ**ちょうどその個体 **がイベントを起こしたのか」という条件付き確率を考えます。時刻 でリスクにある全員のハザードは 。その中で個体 がイベントを起こす条件付き確率は、ハザードの比
ここで分子・分母の がきれいに約分されて消えます。これが核心です。これを全イベント時刻でかけ合わせたものが部分尤度です。
要するに「『リスク集合の中で誰がイベントを起こすか』の条件付き確率の積。ベースライン は比を取る過程で消えるので、 だけの関数になる」。これを最大化(対数部分尤度の偏微分=0)して を得ます。最尤法と同じ枠組み(最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論))ですが、尤度の「一部(イベントの順序情報)」しか使わないので部分尤度と呼ばれます。具体的な生存時刻の値そのものは使わず、イベントが起きた順序とそのときのリスク集合だけで が決まる点が美しいところです。
なぜ を捨てても が推定できるのか:知りたいのは「共変量が効くか()」であって「時間とともにベースラインがどう動くか()」ではありません。比例ハザード構造のおかげで、 という邪魔者(局外パラメータ)を約分で消し、興味のある だけを取り出せるのです。
8. 引っかけ・頻出論点
- ⚠️ 打ち切りは欠測ではない:欠測は「データそのものが無い」状態。打ち切りは「 という不等式情報がある」状態。打ち切りを単純に除外すると、長命な個体を捨てることになり生存時間を過小評価する。
- ⚠️ ハザードは確率ではなく『率』: は単位時間あたりの瞬間発生率で、 を超えてもよい。「ハザードが だから確率が ?」は誤り。確率なのは と 。
- ⚠️ KM法で打ち切りは段差を作らない:打ち切り時刻では なので は下がらない。下がるのはイベント時刻だけ。ただし打ち切りは次以降のリスク集合 を減らす(分母に効く)。
- ⚠️ 比例ハザード仮定が崩れるとCoxは使えない:2群のハザード比が時間とともに変わる(例:KM曲線が途中で交差する)場合、比例ハザードは成立せず、Coxの推定値の解釈が崩れる。1級ではこの仮定の検証(Schoenfeld残差・ プロットの平行性など)が論点。
- ⚠️ ハザード比 ≠ リスク比・オッズ比: はハザード(瞬間率)の比であって、累積発生リスクの比でも生存確率の比でもない。混同しない。
- ⚠️ Coxは「分布を仮定しない」が「比例性は仮定する」:ベースライン の形は自由(半パラメトリックの強み)だが、ハザードが比例するという制約は課している。「Coxは何も仮定しない」は誤り。
試験での問われ方(級ごとの差)
生存時間解析は準1級・1級(特に応用「医薬生物学」分野)で扱われますが、毎回必ず出るわけではありません(出題範囲・配点は改訂されうるため要最新確認)。級で問われる深さが明確に違います。
準1級レベル
ここで問われるのは「計算と解釈」。KM推定量を表から手計算できるか、生存とハザードの関係式を使えるか、ハザード比 を言葉で解釈できるか。
- カプラン・マイヤー推定量の手計算:打ち切り入りデータから を で求める。打ち切りがリスク集合 を減らすことを正しく扱えるか。
- 、 の関係式を使った計算(指数分布の定数ハザードなど)。
- Cox回帰のハザード比の解釈: が「共変量1単位増でハザード何倍か」を答える。 の符号と危険因子/保護因子の対応。
- ログランク検定:2群比較の目的と、期待死亡数 の意味の理解。
1級レベル
ここで問われるのは「導出と検証」。関係式を導き、部分尤度を構成し、比例ハザード仮定の妥当性まで論じられるか。
- 、 の導出(第3節)を自分で書く。
- 部分尤度 の構成(第7.3節):リスク集合上の条件付き確率として導き、 が約分で消える仕組みを説明する。対数部分尤度の最大化で を得る。
- 比例ハザード仮定の検証:仮定が崩れる状況(KM曲線の交差)と検証法( の平行性、Schoenfeld残差など)。
- KM推定量が打ち切り込み尤度のノンパラメトリック最尤推定量であること、ログランク統計量の漸近的カイ二乗性などの理論的背景。
応用「医薬生物学」では臨床試験の文脈(無作為化・エンドポイント・ハザード比の報告)と結びつけて問われます。一般化線形モデルとの違い(一般化線形モデル(ロジスティック・ポアソン回帰))、最尤法の枠組み(最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論))が前提です。
よくある疑問(Q&A)
Q1. 打ち切りデータは「分からないデータ」なのに、なぜ捨てずに使えるのですか?
打ち切りは「完全に分からない」のではなく「(少なくとも までは生きた)」という不等式の情報を持っているからです。KM法はこれを「リスク集合 に まで居続けて分母に貢献し、 で退場する」という形で使います。むしろ捨てる方が危険で、打ち切りは長命な個体に多いため、除外すると短命な個体ばかり残って生存時間を過小評価します。「情報がある以上、捨てない」のが生存時間解析の出発点です。
Q2. ハザードが「率」で確率ではない、というのがピンときません。 を超えるとは?
ハザード は「単位時間あたりのイベント発生の勢い」で、確率を時間で割ったものです()。割り算で時間の逆数の次元を持つので、/年を超えることも普通にあります。例えば /年なら「このペースが続けば1年で平均2回イベントが起きる強さ」という意味で、確率の ではありません。実際にある瞬間にイベントが起きる確率は (微小)で、これはちゃんと 以下です。確率なのは 、率なのが 、と分けて覚えてください。
Q3. Cox回帰は「ベースラインハザード を推定しない」のに、どうやって予測するのですか?
の推定(部分尤度)には は要りませんが、個別の生存確率 を予測したいときは (または累積ベースライン )の推定が別途必要です。これは を得たあとに Breslow 推定量などでノンパラメトリックに推定します。つまり「効果 を知るだけなら 不要、生存曲線を描くなら も推定」と段階が分かれています。準1級で問われるハザード比の解釈は前者( だけ)で完結します。
Q4. ログランク検定とCox回帰は何が違うのですか? どちらを使えばいいですか?
ログランク検定は「2群(やk群)に差があるか/ないか」のYES/NO(仮説検定)で、共変量は群のラベル1つだけです。Cox回帰は「各共変量がハザードを何倍にするか」を連続値も含めて定量化(モデリング)し、複数の共変量を同時に調整できます。実は、共変量が2群の指示変数1つだけのとき、Coxのスコア検定はログランク検定とほぼ一致します。使い分けは「差の有無だけ知りたい→ログランク」「効果の大きさや交絡調整が要る→Cox」です。
Q5. 比例ハザード仮定が成り立たないと、具体的に何が起きるのですか?
ハザード比 が「時間によらず一定」でなくなるので、Coxが推定する単一の がどの時点の比なのか意味不明になります。典型的な兆候は、2群のKM曲線が途中で交差すること(最初は治療群が有利でも後半で逆転するなど)。このとき「平均的なハザード比」を1つ報告しても誤解を招きます。1級では を群ごとにプロットして平行かを見る、Schoenfeld残差が時間と無相関かを調べる、といった検証法が問われます。崩れている場合は時間依存共変量を入れる、層別Cox、別モデル(加速故障時間モデル)などで対処します。
まとめ
- 生存時間解析は「イベントまでの時間 」を扱い、**打ち切り( の情報)**が必ず混じるので専用手法が要る。打ち切りは欠測ではなく、捨てると生存時間を過小評価する。
- 3つの関数 、、 は同値で、 を積分して が導ける。
- パラメトリック例:定数ハザード = 指数分布(無記憶)、ワイブルは形状 で単調増加/一定/減少を表す。
- カプラン・マイヤー は打ち切りをリスク集合 の減少で扱う階段関数。打ち切り時刻では段差なし。
- ログランク検定:各イベント時刻の 表から期待死亡数 を作り、 で2群を比較(自由度1)。
- Cox比例ハザード :ハザード比 は時間によらず一定(比例ハザード仮定)。 は が約分で消える部分尤度で推定する半パラメトリック法。
- 準1級は計算と解釈(KM・ハザード比)、1級は導出と検証(部分尤度・比例ハザード仮定)。
関連ノート
- 一般化線形モデル(ロジスティック・ポアソン回帰) Coxとの対比。GLMは分布を完全に仮定、Coxはベースラインをノンパラに残す半パラメトリック
- 指数分布・ガンマ分布・ベータ分布 定数ハザード=指数分布、ワイブルの土台となる連続分布
- 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) 部分尤度・KM推定量の背後にある最尤推定の枠組み
- ポアソン分布 無記憶性・指数分布の到着間隔としてのつながり
- ノンパラメトリック検定(符号・順位和・Wilcoxon) ログランク検定はノンパラ的な2群比較(順序情報を使う検定)の生存版
- 確率変数(離散・連続)と期待値・分散 生存関数・ハザード・期待値の定義の土台
- 確率過程・時系列・応用(Phase 8 目次) 確率過程・時系列・応用ドメインの全体地図