📊 対象級:1級 | 重要度:B(標準)
要点(BLUF)
状態空間モデルは、時系列を「見えない状態 の時間発展」と「その状態をノイズ越しに観測した結果 」の二段構えで書く枠組みです。前者を状態方程式、後者を観測方程式と呼びます。
要するに「真の状態は裏で勝手に動いていて(状態方程式)、我々はそれを雑音まみれで覗いているだけ(観測方程式)」。この は潜在変数で、直接は見えません。
雑音がすべて正規分布なら線形ガウス状態空間モデルと呼び、このとき状態を逐次推定する最適アルゴリズムがカルマンフィルタです。カルマンフィルタの正体は「予測(事前分布を作る)→ 更新(観測でベイズ更新して事後分布にする)」を1ステップずつ繰り返すだけ——つまり 事前分布・事後分布・ベイズ更新 の多変量正規版を毎時刻やっているものです。状態空間表現はARIMAも局所水準モデルも一つの形に統一でき(時系列解析(定常性・ACF/PACF・AR・MA・ARMA・ARIMA) の手法群を包含する)、1級(統計応用)では式の意味の理解が問われます(範囲・配点は改訂されうるため要最新確認)。
1. 状態空間表現とは(状態方程式+観測方程式)
時系列モデリングの発想を一段抽象化します。観測される系列 を直接モデル化するのではなく、その背後に見えない状態 (状態ベクトル)を想定し、
- 状態がどう時間発展するか(状態方程式=システムモデル)
- 状態がどう観測に現れるか(観測方程式=観測モデル)
の2本に分けて書きます。線形・時不変な書き方は次の通りです(係数行列 は時刻に依存してもよいが、ここでは固定とします)。
各記号の役割:
| 記号 | 名前 | 意味 |
|---|---|---|
| 状態ベクトル | 見えない真の状態(潜在変数)。次元は | |
| 観測ベクトル | 実際に手に入るデータ。次元は | |
| 状態遷移行列 | 状態が1ステップでどう動くか | |
| 観測行列 | 状態を観測へ写す変換(観測されるのは状態の一部 or 一次結合) | |
| システム雑音の共分散 | 状態発展の不確かさ | |
| 観測雑音の共分散 | 観測の不確かさ(測定誤差) | |
| 雑音 | 互いに独立・時間方向に独立な平均0の雑音 |
要するに「状態は で転がりながら雑音 でブレ、それを 越しに雑音 込みで観測する」。状態 が直接見えない以上、データ から を推し量るのが本質的な課題になります。状態の時間発展(マルコフ性)の土台は 確率過程(マルコフ連鎖・ポアソン過程) のマルコフ過程です。
1.1 なぜわざわざ潜在状態を立てるのか
利点が3つあります。
- 統一性:ARIMA・季節成分・トレンド・回帰を、状態ベクトルの設計だけで一つの枠組みに書ける(後述)。
- 逐次性:データが1点増えるたびに、過去を全部見直さず前回の結果を1ステップ更新するだけで最新の状態推定が得られる(カルマンフィルタ)。リアルタイム処理に向く。
- 欠測・非定常への強さ:欠測時は更新ステップを飛ばせばよく、トレンドのような非定常成分も状態として自然に扱える。
2. 線形ガウス状態空間モデル
上の式で、初期状態と全雑音が正規分布であると仮定したものが線形ガウス状態空間モデルです。
このガウス仮定が決定的に効きます。正規分布は線形変換とベイズ更新(条件付け)に対して閉じている——線形変換しても正規、条件付き分布も正規——ので、状態に関する分布は時刻が進んでもずっと正規分布のままです(多変量正規分布 の性質)。正規分布は平均ベクトルと共分散行列だけで完全に決まるので、状態推定は「平均と共分散をどう更新するか」という有限個の量の計算に帰着します。これがカルマンフィルタが閉じた形(解析解)を持つ理由です。
雑音が正規でない・式が非線形だと、分布は正規でなくなり閉形式が壊れます。その場合は拡張カルマンフィルタ(線形近似)や粒子フィルタ(モンテカルロ近似)に進みますが、本ノートの主役は線形ガウスです(発展は 計量時系列の発展(単位根・共和分・ARCH/GARCH))。
3. カルマンフィルタ(予測→更新の逐次ベイズ推定)
カルマンフィルタは、線形ガウス状態空間モデルで「時刻 までの観測 をすべて使ったときの状態 の分布」(フィルタ分布 )を逐次的に求めるアルゴリズムです。各時刻で2ステップを回します。
flowchart LR
A["前時刻のフィルタ分布<br/>p(x_{t-1} | y_{1:t-1})<br/>= N(状態の事後)"] --> B
B["予測ステップ<br/>状態方程式 x_t = F x_{t-1} + v_t で1歩先へ<br/>→ 事前分布 p(x_t | y_{1:t-1})"] --> C
C{"新しい観測<br/>y_t が到着"} --> D
D["更新ステップ<br/>観測 y_t でベイズ更新<br/>(カルマンゲイン K_t で補正)<br/>→ 事後分布 p(x_t | y_{1:t})"] --> E["今時刻のフィルタ分布<br/>p(x_t | y_{1:t})"]
E -.->|次の時刻 t+1 へ| A
記号を整理します。 を「時刻 までの観測を使った の平均推定値」、 をその共分散とします。 は事前(観測前)、 は事後(観測後)です。
3.1 予測ステップ(事前分布を作る)
前時刻の事後 を、状態方程式 で1ステップ先へ送ります。正規分布の線形変換則(平均は線形変換、共分散は に雑音 を足す)から、
要するに「状態を で1歩進め、不確かさは で引き伸ばしたうえにシステム雑音 ぶん増やす」。観測する前の予想なので、これが時刻 の状態に関する事前分布になります。
3.2 更新ステップ(観測でベイズ更新して事後分布へ)
新しい観測 が来たら、事前分布 を事前、観測方程式 が与える尤度 を尤度として、ベイズの定理で事後分布を求めます。結果は次の更新式です。
まずイノベーション(観測の予測誤差)とカルマンゲイン を定義します。
これを使って事後の平均と共分散を更新します。
要するに「予測 を、外れ具合 に応じて だけ引っ張って補正する。補正したぶん不確かさ も減る」。これが時刻 の事後分布=フィルタ分布で、次の時刻の予測ステップの入力になります。
4. 更新式の導出(多変量正規のベイズ更新そのもの)
カルマンゲインの式は天下りに見えますが、その正体は 「正規事前 × 正規尤度 → 正規事後」という 多変量正規分布 の条件付き分布の公式です。1級ではこの「なぜそうなるか」が問われうるので、骨子を省略せず示します。
4.1 使う補題:正規事前+線形ガウス観測の事後分布
次の補題が核心です(事前分布・事後分布・ベイズ更新 の正規-正規共役の多変量版)。
補題:状態の事前分布が 、観測が のとき、事後分布 もまた正規分布で、
この を予測ステップの事前平均 、 を事前共分散 と読み替えれば、§3.2 の更新式そのものです。つまり更新ステップ=この補題の適用です。
4.2 補題の導出(同時分布を作って条件付ける)
多変量正規分布 の「正規分布の条件付き分布は再び正規」を使います。状態 と観測 を縦に積んだベクトル \begin{psmallmatrix}x\\ y\end{psmallmatrix} の同時分布を作り、 で条件付ければ が出ます。
ステップ1:同時分布のモーメントを計算する。 、(、 と独立)から、各モーメントは
よって同時分布は
要するに「 と をまとめた正規分布の平均と共分散ブロックを、観測方程式から計算しただけ」。
ステップ2:条件付き分布の公式を当てはめる。 多変量正規 \begin{psmallmatrix}x\\ y\end{psmallmatrix}\sim\mathcal N\!\left(\begin{psmallmatrix}\mu_x\\ \mu_y\end{psmallmatrix},\begin{psmallmatrix}\Sigma_{xx}&\Sigma_{xy}\\ \Sigma_{yx}&\Sigma_{yy}\end{psmallmatrix}\right) における条件付き分布の公式(多変量正規分布)
に、ステップ1の各ブロック()を代入します。
要するに「条件付き分布の一般公式に観測方程式のブロックを入れたら、 の部分がそっくりカルマンゲイン になった」。これで補題が示せ、更新ステップがベイズ更新の帰結であることが確定します。
4.3 イノベーションの直交性(最小分散の意味)
別の見方として、カルマンフィルタの推定量 は「 の線形関数の中で平均二乗誤差を最小にする推定量」(線形最小分散推定量)でもあります。導出の要はイノベーション が過去の観測と直交すること—— は「過去から予測できなかった真に新しい情報」だけを含む——で、これを使うと射影定理から同じ更新式が出ます。ガウス性を仮定すれば線形最小分散推定量が条件付き期待値 と一致するため、§4.2 のベイズ導出と§4.3 の射影導出は同じ答えになります。1級では「カルマンフィルタは線形最小分散推定」と「ガウス下では条件付き期待値(=ベイズ最適)」が一致する、という対応関係を押さえると強いです。
5. カルマンゲイン の意味
カルマンゲインは「観測をどれだけ信用して予測を修正するか」の重み( の行列版)です。スカラー(1次元)で見ると直観が明快です。(予測の分散)、、(観測雑音の分散)なら
- (観測が正確):。予測を捨てて観測をほぼそのまま採用()。
- (観測が当てにならない):。観測を無視して予測を維持()。
- が大きい(予測が不確か): 大。観測を重く見る。
要するに「予測の不確かさ と観測の不確かさ を秤にかけ、確かな方を重く採る加重平均の重み」。これは精度(分散の逆数)で重みづけた合成そのもので、 は予測と観測を精度で加重平均した点になります(事後分散 は両者の精度の和の逆数)。ベイズ更新で2つの正規情報を統合するときの標準的な振る舞いです。
6. ARIMAの状態空間表現
状態空間表現の強みは、多くの時系列モデルを一つの形に書けることです。代表例として ARMA/ARIMA を状態空間に落とせます(時系列解析(定常性・ACF/PACF・AR・MA・ARMA・ARIMA) の ARIMA を統一的に扱う)。
例として AR(2) を考えます。状態ベクトルを x_t=\begin{psmallmatrix}y_t\\ y_{t-1}\end{psmallmatrix} と取れば、
要するに「過去のラグを状態ベクトルに詰め込めば、AR の漸化式が状態方程式 の形になる」。一般の ARMA() も次元を増やせば同様に書け、差分 階の I(和分)は状態に和分成分を加えることで ARIMA も表現できます。こうして ARIMA を状態空間に書けば、尤度評価・欠測処理・パラメータ推定をすべてカルマンフィルタで統一的に行えます(尤度は §7 のイノベーションから組み立てる)。これが状態空間表現を経由する実務上の最大の利点です。
7. 構造時系列モデル(局所水準・ローカルトレンド)
状態空間のもう一つの使い方は、時系列を意味のある成分(水準・傾き・季節)に分解する構造時系列モデルです。代表が局所水準モデルとローカルトレンドモデルです。
7.1 局所水準モデル(ローカルレベルモデル)
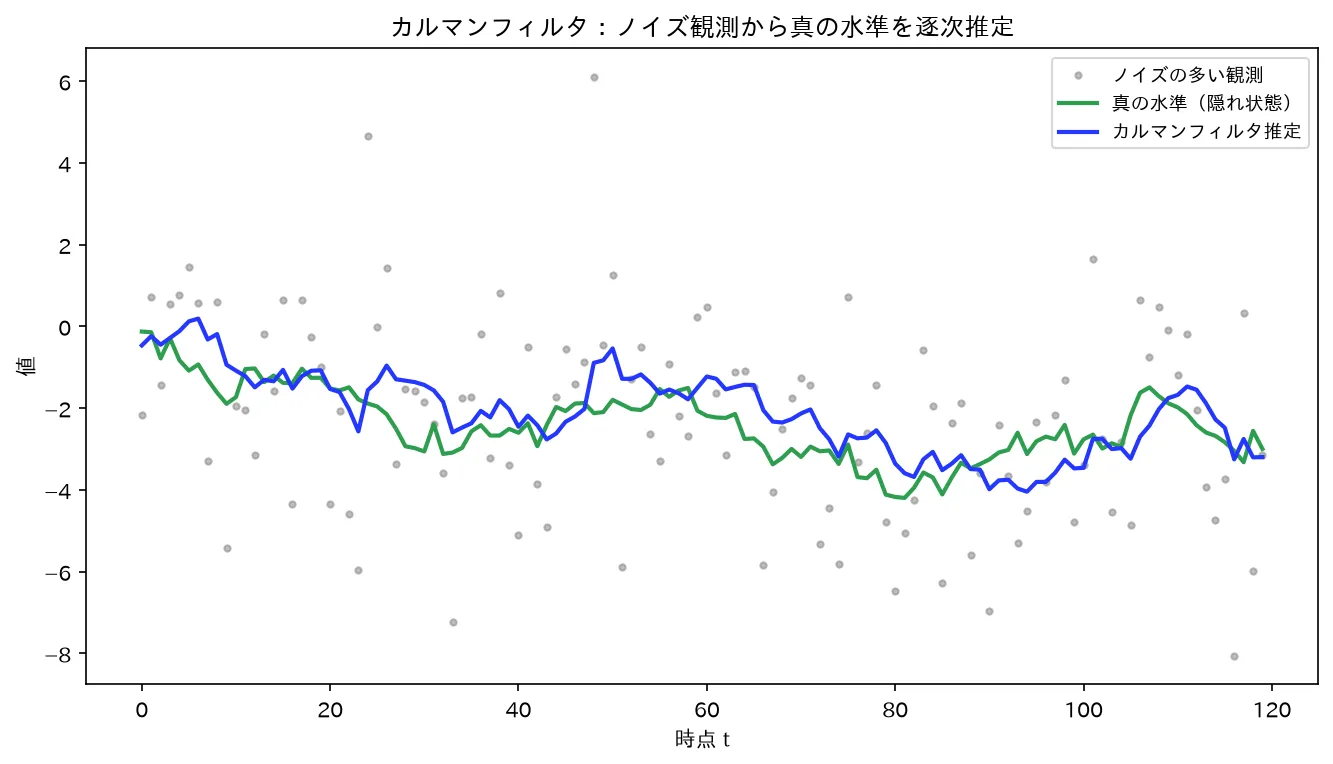
ノイズだらけの観測(灰)から、カルマンフィルタ(青)が背後の真の水準(緑)を逐次推定して滑らかに追従する(予測→更新の逐次ベイズ)。図は simulations/kalman_local_level.py で生成。
最も単純な構造モデル。水準 (状態)がランダムウォークし、それを雑音込みで観測します。
要するに「真の水準 はゆっくり漂い(ランダムウォーク)、観測 はそれに測定誤差が乗ったもの」。 の最小の状態空間モデルで、移動平均的な平滑化を確率モデルとして正当化したものと見られます。 の比が「水準をどれだけ機敏に追従させるか」を決めます。
7.2 ローカルトレンドモデル(局所線形トレンドモデル)
水準 に加えて傾き(トレンド) も状態として持たせ、両方がランダムウォークするモデルです。
要するに「水準は前の水準に傾きを足して進み、その傾き自体もゆっくり変化する」。状態ベクトル x_t=\begin{psmallmatrix}\mu_t\\ \nu_t\end{psmallmatrix} で書けば F=\begin{psmallmatrix}1&1\\0&1\end{psmallmatrix}、H=\begin{psmallmatrix}1&0\end{psmallmatrix} の線形ガウスモデルになり、カルマンフィルタがそのまま使えます。さらに季節成分を状態に足せば季節調整モデルになり、トレンド・季節・回帰を部品の足し算で組めるのが構造時系列の柔軟さです。
8. フィルタリングと平滑化(推定の3タイプ)
状態推定は「どの時点までの観測を使って、どの時点の状態を推定するか」で3つに分かれます。ここは1級で区別を問われやすい論点です。
| 種類 | 推定対象 | 使う観測 | 分布 |
|---|---|---|---|
| 予測(prediction) | 未来 or 現在の状態 | 現在まで | |
| フィルタリング(filtering) | 現在の状態 | 現在まで | |
| 平滑化(smoothing) | 過去の状態 | 全期間 (未来も含む) |
- フィルタリングは「今までのデータで今を推定」。カルマンフィルタの前向き再帰がこれを与えます。リアルタイム向き。
- 平滑化は「未来も含む全データで過去を推定し直す」。全データが揃ってから、フィルタの結果を後ろ向きに走らせる再帰(固定区間平滑化)で計算します。未来の情報も使えるぶん、平滑化はフィルタリングより必ず分散が小さく(精度が高く)なります。
要するに「フィルタ=逐次・リアルタイム、平滑化=全データを使った過去の精緻化」。時系列を後から分析する(成分分解・トレンド抽出)目的なら平滑化、オンラインで状態を追う目的ならフィルタリングを使います。
9. 引っかけ・頻出論点
- ⚠️ 状態は潜在変数(直接観測されない): は見えず、見えるのは だけ。「観測値そのものを状態と思う」のは誤り。観測は状態の雑音つき一次変換です。
- ⚠️ フィルタ ≠ 平滑化:フィルタリングは「 で 」(現在まで→現在)、平滑化は「 で 」(全データ→過去)。平滑化のほうが分散が小さい(未来情報も使うから)。「カルマンフィルタ=平滑化」と混同しないこと。
- ⚠️ カルマンゲインは観測への信頼度の重み: が大きい=観測を重く採る(観測が正確 or 予測が不確か)。 で、(観測雑音)が小さいほど は大きい。「ゲインが大きいほど予測を信じる」は逆。
- ⚠️ 予測は不確かさを増やし、更新は減らす:予測ステップで は ぶん増える、更新ステップで がかかり減る。この増減の交代がフィルタの呼吸です。「常に分散が減る」わけではない。
- ⚠️ 線形ガウスだから閉形式:解析解が出るのは線形かつ正規だから。非線形・非ガウスでは分布が正規でなくなり、拡張カルマンフィルタ/粒子フィルタが必要(計量時系列の発展(単位根・共和分・ARCH/GARCH))。
- ⚠️ ガウス下でフィルタ=ベイズ最適:線形ガウスなら、カルマンフィルタの出力は条件付き期待値 (平均二乗誤差最小のベイズ推定量)に一致する。ガウスでない場合は「線形最小分散推定」止まりで、必ずしもベイズ最適ではない。
試験での問われ方(1級)
1級(統計応用、とくに「理工学」「経済」分野の時系列)で、状態空間モデルは標準的な論点です(範囲・配点は改訂されうるため要最新確認)。典型的な問われ方:
- 状態方程式・観測方程式の定式化:与えられた時系列(局所水準・トレンド・AR)を状態空間表現に書き、 を同定する。
- カルマンフィルタの1ステップ計算:与えられた と新観測 から、予測 → カルマンゲイン → 更新を数値で1巡計算する(スカラー or 2次元)。
- カルマンゲインの解釈: が観測雑音 ・予測分散 にどう依存し、何を意味するかを説明する。
- 更新式の根拠:更新ステップが正規分布のベイズ更新(条件付き分布)から出ることを論述する(§4 の骨子)。
- フィルタリングと平滑化の区別:使う情報・推定対象・精度の違いを説明する。
前提として多変量正規分布の条件付き分布(多変量正規分布)、ベイズ更新(事前分布・事後分布・ベイズ更新)、ARIMA(時系列解析(定常性・ACF/PACF・AR・MA・ARMA・ARIMA))が使えることが要求されます。
よくある疑問(Q&A)
Q1. 状態 と観測 は何が違うのですか? 同じ時系列に見えます。
役割がまったく違います。 は真の・見えない状態(潜在変数)で、システムの中で に従って勝手に時間発展します。 はそれを雑音越しに観測した結果で、 と「状態の一次変換+測定誤差」になっています。手に入るのは だけで、 は推定するしかない——この「見えないものを観測から推し量る」構造が状態空間モデルの本質です。例えば =真の景気、=雑音まみれの景気指標、と考えると分かりやすいです。
Q2. カルマンフィルタの更新式(特にカルマンゲイン)は暗記するしかないのですか?
暗記不要です。更新ステップは「正規事前 × 正規尤度 → 正規事後」というベイズ更新そのもので、多変量正規の条件付き分布の公式 に観測方程式のブロックを代入すると、 がそのままカルマンゲイン として出てきます(§4.2)。導出の流れさえ押さえれば、式は再構成できます。
Q3. フィルタリングと平滑化、どちらが「良い」推定なのですか?
目的次第ですが、精度(分散の小ささ)では平滑化が必ず勝ちます。平滑化は未来も含む全データ を使って過去の状態を推定し直すので、現在までしか使わないフィルタリングより情報が多く、分散が小さくなります。ただし平滑化は全データが揃ってから後ろ向きに計算するため、リアルタイムには使えません。オンラインで「今」を追うならフィルタリング、後から腰を据えて時系列を分解・分析するなら平滑化、という使い分けです。
Q4. なぜガウス(正規分布)の仮定がそんなに重要なのですか?
正規分布が線形変換とベイズ更新(条件付け)に対して閉じているからです。状態を で線形変換しても正規、観測でベイズ更新しても(条件付き分布も)正規——だから状態に関する分布は時刻が進んでも正規のまま保たれます。正規分布は平均と共分散だけで完全に決まるので、無限次元の関数(確率分布)の更新が、有限個の数(平均ベクトルと共分散行列)の更新に圧縮できます。これがカルマンフィルタが閉じた解析解を持つ理由です。非ガウスだと分布が複雑化し、この圧縮が効きません。
Q5. ARIMAで足りるのに、わざわざ状態空間で書く意味は?
統一性と汎用性です。状態空間に書けば、ARIMA・トレンド・季節・回帰・欠測を一つの枠組みとカルマンフィルタという単一のエンジンで扱えます。具体的な利点として、(1) 欠測があってもその時刻の更新ステップを飛ばすだけで自然に対応でき、(2) 尤度をイノベーションから組み立てて最尤推定でき、(3) トレンドや季節のような非定常成分を状態として直接モデル化できます。ARIMA単体では面倒な「欠測・成分分解・時変パラメータ」が、状態ベクトルの設計だけで統一的に書けるのが状態空間表現の強みです。
Q6. カルマンゲインが「大きい」とは、結局どういう状況ですか?
「観測を信用して、予測を大きく修正する」状況です。 なので、観測雑音 が小さい(観測が正確)か、予測の不確かさ が大きい(予測が当てにならない)ときに は大きくなります。スカラーなら で、 なら (観測をほぼ丸ごと採用)、 なら (観測を無視して予測を維持)。要は予測と観測の確からしさを秤にかけた重みで、確かな方を重く採ります。
まとめ
- 状態空間モデルは時系列を「見えない状態の時間発展(状態方程式 )」と「状態の雑音つき観測(観測方程式 )」の二段で書く枠組み。 は潜在変数。
- 雑音がすべて正規なら線形ガウス状態空間モデル。正規分布が線形変換・条件付けに閉じているので、状態の分布は常に正規に保たれ、平均と共分散の更新だけで状態推定できる。
- カルマンフィルタ=予測(状態方程式で1歩進め事前分布を作る:、)→ 更新(観測でベイズ更新し事後分布へ:カルマンゲイン 、)の逐次推定。
- 更新式の正体は多変量正規の条件付き分布(ベイズ更新)。\begin{psmallmatrix}x\\ y\end{psmallmatrix} の同時正規分布を作り で条件付けると、 がカルマンゲインになる。
- カルマンゲインは観測への信頼度の重み(精度で加重平均)。観測が正確 or 予測が不確かなとき大。
- ARIMA・局所水準・ローカルトレンドはすべて状態空間に書け、カルマンフィルタで統一的に推定できる。
- 推定の3タイプ:予測(現在まで→未来)/フィルタリング(現在まで→現在・逐次)/平滑化(全データ→過去・最も高精度だがオフライン)。
関連ノート
- 時系列解析(定常性・ACF/PACF・AR・MA・ARMA・ARIMA) ARIMA・ARMA。状態空間表現はこれらを統一的に書き、カルマンフィルタで尤度評価・推定する受け皿
- 確率過程(マルコフ連鎖・ポアソン過程) 状態の時間発展はマルコフ過程。状態方程式 はマルコフ性そのもの
- 事前分布・事後分布・ベイズ更新 更新ステップ=正規事前×正規尤度のベイズ更新。カルマンフィルタは毎時刻これを回している
- 多変量正規分布 更新式の導出の核。条件付き分布の公式からカルマンゲインが出る。正規が線形変換・条件付けに閉じることが閉形式の根拠
- 計量時系列の発展(単位根・共和分・ARCH/GARCH) 非線形・非ガウスへの拡張(拡張カルマンフィルタ・粒子フィルタ)。本ノートの線形ガウスの先
- 1級「統計応用」(Phase 9 目次) 統計応用ドメインの全体地図