← 統計検定テキスト 一覧
📊 対象級:1級 | 重要度:B(標準)
要点(BLUF)
推定量 θ^ が漸近正規(n(θ^−θ)dN(0,σ2))なら、その滑らかな関数 g(θ^) もまた漸近正規で、分散は g′(θ)2σ2 になります。これがデルタ法です。証明は「g を1次テイラー展開して、傾き g′(θ^) をスルツキー定理で g′(θ) に差し替える」だけ。推定量を変換したときの標準誤差を出す万能道具で、ここから分散安定化変換も自然に導けます。
- デルタ法:n(θ^−θ)dN(0,σ2) のとき、g′(θ)=0 なら n(g(θ^)−g(θ))dN(0,g′(θ)2σ2)。要するに「変換後の漸近分散は、元の分散に傾きの2乗 g′(θ)2 を掛けたもの」。
- 多変量デルタ法:n(θ^−θ)dN(0,Σ) のとき、スカラー関数 g の漸近分散は ∇g(θ)⊤Σ∇g(θ)。傾きが勾配ベクトルに、2乗が**Σ を挟む2次形式**に置き換わるだけ。
- 分散安定化変換:漸近分散 V(θ) が θ に依存して困るとき、g′(θ)∝1/V(θ) を満たす g を選ぶと変換後の分散が**θ によらない定数になる。代表例はポアソンの X、二項比率の arcsinp^、相関係数のフィッシャーのz変換** 21ln1−r1+r。
1級(統計応用・理工学)では推定量の関数の標準誤差計算・分散安定化変換の導出として問われます(範囲・配点は改訂されうるため要最新確認)。土台は大数の法則・中心極限定理・最尤推定量の漸近正規性です。
graph TD
ROOT["漸近正規性<br/>√n(θ̂−θ) → N(0, σ²)"] --> DM["デルタ法<br/>√n(g(θ̂)−g(θ)) → N(0, g'(θ)²σ²)"]
DM --> MV["多変量デルタ法<br/>分散 = ∇g(θ)ᵀ Σ ∇g(θ)"]
DM --> VST["分散安定化変換<br/>g'(θ) ∝ 1/√V(θ) で分散を定数化"]
DM --> SECOND["g'(θ)=0 のとき<br/>2次のデルタ法 → χ²₁ が出る"]
VST --> EX["√X(ポアソン)<br/>arcsin√p̂(二項比率)<br/>フィッシャーz(相関)"]
1. デルタ法 — 推定量を変換したらどうなるか
1.1 問題設定
最尤推定量や標本平均は、たいてい次の形の漸近正規性を満たします(中心極限定理や最尤推定量の一般論から)。
n(θ^−θ)dN(0,σ2)
要するに「θ^ は真値 θ のまわりに、おおよそ N(θ,σ2/n) でばらつく」。標本を増やすと σ2/n→0 で1点に潰れます。
ところが知りたいのは θ そのものではなく、θ の関数 g(θ) であることが多い。たとえば指数分布のレート λ ではなく平均 1/λ、ベルヌーイの確率 p ではなくオッズ p/(1−p) など。このとき g(θ^) の分布はどうなるか——それに答えるのがデルタ法です。
1.2 導出(1次テイラー展開+スルツキー定理)
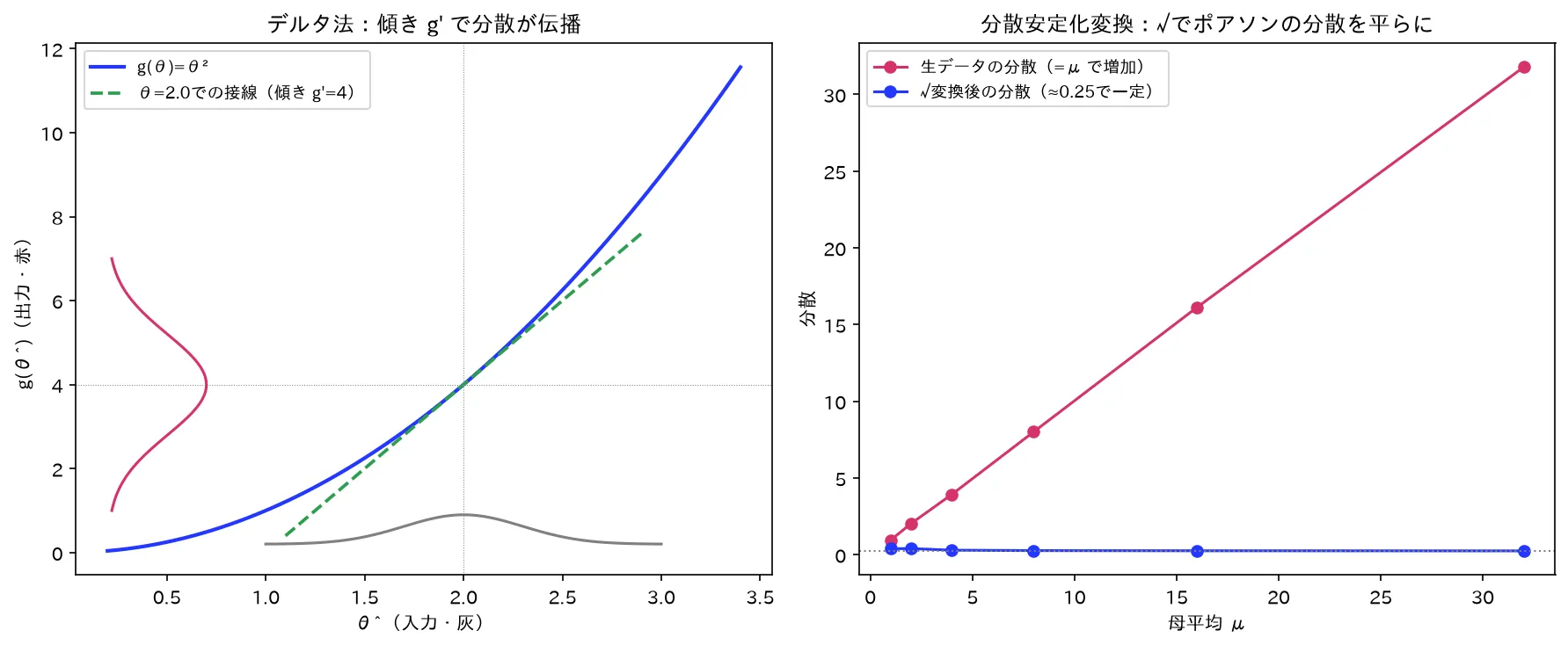
図は simulations/delta_hou_keijou.py で生成。
結論を先に。g が θ で微分可能で g′(θ)=0 なら、
n(g(θ^)−g(θ))dN(0,g′(θ)2σ2)
導出は3ステップです。
ステップ1:1次テイラー展開(平均値の定理). g を θ のまわりで展開します。平均値の定理を使うと、θ^ と θ の間にある点 θ~ を使って剰余項なしで書けます。
g(θ^)=g(θ)+g′(θ~)(θ^−θ),θ~∈(θ,θ^)
要するに「g(θ^) と g(θ) の差は、傾き g′(θ~) かける (θ^−θ)」。これを移項して n を掛けます。
n(g(θ^)−g(θ))=g′(θ~)⋅n(θ^−θ)
ステップ2:傾きを g′(θ) に差し替える. θ^pθ なので(漸近正規なら一致もする)、間に挟まれた θ~ も θ~pθ。g′ が連続なら連続写像定理により
g′(θ~)pg′(θ)
要するに「θ^ が真値に近づくにつれ、テイラー展開の傾きも真の点の傾き g′(θ) に近づく」。g′(θ) はただの定数です。
ステップ3:スルツキー定理で合体. いま手元には2つの量があります。
- g′(θ~)pg′(θ)(定数に確率収束)
- n(θ^−θ)dN(0,σ2)(分布収束)
スルツキー定理は「定数に確率収束する量 × 分布収束する量は、その定数を掛けた分布に分布収束する」と言います。よって積は
g′(θ~)⋅n(θ^−θ)dg′(θ)⋅N(0,σ2)=N(0,g′(θ)2σ2)
正規分布を定数 c=g′(θ) 倍すると分散は c2 倍になる(Var(cZ)=c2Var(Z))ので、分散が g′(θ)2σ2 になります。これで導出完了です。
💡 導出の心臓部は「非線形な g を、真の点 θ のまわりで直線(接線)に置き換える」こと。接線の傾きが g′(θ) で、漸近的には θ^ が θ のすぐ近くにしかいないので、その狭い範囲では g は接線とほぼ同じ。直線変換は正規分布を正規分布に保ち、傾きの2乗だけ分散を伸縮する——それがデルタ法の正体です。
1.3 実用形:標準誤差の計算
漸近分布が分かれば**標準誤差(SE)**が出せます。θ^ の標準誤差が SE(θ^) のとき、変換後は
SE(g(θ^))≈g′(θ^)⋅SE(θ^)
要するに「変換後のSEは、元のSEに傾きの絶対値 ∣g′(θ^)∣ を掛ける」(n が両辺で約分され、θ は推定値 θ^ で置く)。これが1級でデルタ法を使う最頻出の場面です。
例:オッズの標準誤差. ベルヌーイ試行で p^ の漸近分散が p(1−p)/n のとき、オッズ g(p)=p/(1−p) の標準誤差を求めます。g′(p)=(1−p)21 なので、
Var(g(p^))≈[(1−p)21]2⋅np(1−p)=n(1−p)3p
要するに「p^ の分散に g′ の2乗を掛ければオッズの分散になる」。p が1に近いとオッズの分散が爆発する(分母 (1−p)3)ことも式から読めます。
2. 多変量デルタ法
2.1 勾配とヤコビアン
推定量がベクトル θ^=(θ^1,…,θ^k)⊤ で、漸近的に多変量正規
n(θ^−θ)dN(0,Σ)
を満たすとします(Σ は k×k の漸近共分散行列)。このときスカラー値の滑らかな関数 g:Rk→R について、
n(g(θ^)−g(θ))dN(0,∇g(θ)⊤Σ∇g(θ))
ここで ∇g(θ)=(∂g/∂θ1,…,∂g/∂θk)⊤ は勾配ベクトルです。要するに「1変数の g′(θ) が勾配ベクトル ∇g に、g′(θ)2σ2 が Σ を勾配で挟む2次形式 ∇g⊤Σ∇g に置き換わるだけ」。
導出は1変数とまったく同じ筋です。1次の多変量テイラー展開
g(θ^)≈g(θ)+∇g(θ)⊤(θ^−θ)
の両辺に n を掛け、∇g(θ) を定数ベクトルとみてスルツキー定理を適用します。多変量正規 N(0,Σ) を定数ベクトル a=∇g(θ) で線形結合した a⊤X の分散は a⊤Σa(正規分布の線形結合の公式)なので、上の2次形式が出ます。
💡 出力がベクトル値の関数 g:Rk→Rm なら、勾配ベクトルはヤコビ行列 J=∂g/∂θ(m×k)に一般化され、漸近共分散は JΣJ⊤(m×m)になります。スカラー版はこの m=1 の特別な場合です。
2.2 例:比の分散
2つの推定量の比 g(θ1,θ2)=θ1/θ2 の漸近分散を求めます。勾配は
∇g=(∂θ1∂g,∂θ2∂g)⊤=(θ21,−θ22θ1)⊤
漸近共分散行列を Σ=(σ12σ12σ12σ22) とすると、2次形式 ∇g⊤Σ∇g を展開して
Var(θ^2θ^1)≈n1(θ22σ12−θ232θ1σ12+θ24θ12σ22)
要するに「比の分散には分子・分母それぞれの分散だけでなく、両者の共分散 σ12 も効く」。θ1,θ2 が相関していれば交差項を落としてはいけません。これは多変量デルタ法を使わないと正しく出せない典型例です。
3. 分散安定化変換 — 漸近分散を定数にする
3.1 動機と一般原理
デルタ法の式 Var(g(θ^))≈g′(θ)2V(θ) を逆に読みます。多くの分布で漸近分散 V(θ) が母数 θ に依存します(ポアソンなら分散=平均、二項なら p(1−p)、相関係数なら (1−ρ2)2)。これは不便です——信頼区間の幅が母数の値で変わり、θ の値を知らないと区間が引けない、分散分析の等分散仮定が崩れる、などの問題が起きます。
そこで「変換後の分散 g′(θ)2V(θ) が θ によらない定数になるような g」を探します。定数になる条件は
g′(θ)2V(θ)=const⟺g′(θ)∝V(θ)1
要するに「傾き g′ を、分散の平方根の逆数に比例させればよい」。V が大きい(ばらつきやすい)ところでは g を緩やかに、V が小さいところでは急にすることで、変換後のばらつきを一定に均す、という発想です。これを積分して
g(θ)=∫V(θ)1dθ
が分散安定化変換です。以下の3つの代表例は、すべてこの1本の積分から出ます。
flowchart TD
START["漸近分散 V(θ) が θ に依存して困る"] --> COND["条件:g'(θ)²·V(θ) = 定数<br/>⟺ g'(θ) ∝ 1/√V(θ)"]
COND --> INT["積分:g(θ) = ∫ dθ / √V(θ)"]
INT --> P["V=μ(ポアソン)<br/>→ ∫dμ/√μ = 2√μ<br/>変換 √X、分散 ≈ 1/4"]
INT --> B["V=p(1−p)(二項比率)<br/>→ ∫dp/√(p(1−p)) = 2·arcsin√p<br/>変換 arcsin√p̂、分散 ≈ 1/(4n)"]
INT --> R["V=(1−ρ²)²(相関)<br/>→ ∫dρ/(1−ρ²) = artanh ρ<br/>フィッシャーz、分散 ≈ 1/(n−3)"]
3.2 ポアソン分布:平方根変換 X
ポアソン分布は分散=平均 V(μ)=μ という性質を持ちます(母数 μ が大きいほどばらつく)。これを積分します。
g(μ)=∫μ1dμ=2μ
定数倍は分散安定化に影響しない(傾きを定数倍しても分散の比は変わらない)ので、g(μ)=μ と取れます。よって観測値の平方根 X が分散安定化変換です。変換後の漸近分散は
Var(X)≈(2μ1)2⋅μ=41
要するに「X を取ると、平均 μ がいくつであっても分散がほぼ 1/4 で一定になる」。ポアソン計数データを分散分析や回帰にかける前処理として古典的に使われます。
3.3 二項比率:逆正弦(arcsin)変換 arcsinp^
標本比率 p^ の漸近分散は V(p)=p(1−p)/n。1/n は定数なので、θ=p について V(p)∝p(1−p) を積分します。
g(p)=∫p(1−p)1dp
この積分は標準形です。p=sin2u と置くと dp=2sinucosudu、p(1−p)=sinucosu なので
g(p)=∫sinucosu2sinucosudu=2u=2arcsinp
定数倍を落として g(p)=arcsinp^ が**逆正弦変換(arcsine / angular transformation)**です。変換後の漸近分散は
Var(arcsinp^)≈(2p(1−p)1)2⋅np(1−p)=4n1
要するに「arcsinp^ を取ると、p がいくつでも分散がほぼ 1/(4n) で一定になる」。p が0や1に近いと p^ の分散が極端に小さくなる(端で潰れる)のを、変換が引き伸ばして均します。
⚠️ ただし p が0や1の極端では逆正弦変換の近似は良くありません(メタアナリシス等での arcsin 系変換には批判もあり、用途次第で別の変換が推奨される——要最新確認)。試験では「分散安定化変換として導出できること」が主眼です。
3.4 相関係数:フィッシャーのz変換
標本相関係数 r は、母相関 ρ のもとで漸近的に
n(r−ρ)dN(0,(1−ρ2)2)
を満たします。すなわち V(ρ)=(1−ρ2)2。これは ρ への依存が強く(ρ が ±1 に近いと分散が0に潰れ、分布も激しく歪む)、r をそのまま正規近似で扱うのは危険です。積分します。
g(ρ)=∫(1−ρ2)21dρ=∫1−ρ21dρ=21ln1−ρ1+ρ=artanhρ
これがフィッシャーのz変換 z=21ln1−r1+r(逆双曲線正接 artanhr)です。変換後の漸近分散は
Var(z)≈(1−ρ21)2⋅n(1−ρ2)2=n1
要するに「z変換すると、ρ がいくつでも分散がほぼ 1/n で一定になる」。実用上は精度を上げた補正 Var(z)≈n−31 を使い、z∼N(artanhρ,n−31) として相関の信頼区間や検定を行います。区間を z で作ってから tanh で r のスケールに戻すのが定石です。
| 分布 | 漸近分散 V(θ) | 変換 g | 変換後の分散 |
|---|
| ポアソン | μ | X | ≈1/4 |
| 二項比率 | p(1−p)/n | arcsinp^ | ≈1/(4n) |
| 相関係数 | (1−ρ2)2/n | z=21ln1−r1+r | ≈1/n(補正 1/(n−3)) |
3つとも「∫dθ/V(θ)」という同じ1本の積分から出ている、という統一的理解が1級では効きます。
4. 1次微分が0のとき — 2次のデルタ法
デルタ法は g′(θ)=0 を前提にしていました。もし g′(θ)=0 だと、漸近分散 g′(θ)2σ2=0 となり「1次近似では g(θ^) のばらつきが消えてしまう」——これは近似が破綻したサインで、より高次の項を見る必要があります。
g′(θ)=0 かつ g′′(θ)=0 のときは2次の項まで展開します。
g(θ^)−g(θ)≈=0g′(θ)(θ^−θ)+21g′′(θ)(θ^−θ)2=21g′′(θ)(θ^−θ)2
ここで n(θ^−θ)dN(0,σ2) なので、n(θ^−θ)2=[n(θ^−θ)]2 は「正規分布の2乗」に分布収束します。標準正規の2乗が χ12 である事実から [n(θ^−θ)/σ]2dχ12、すなわち n(θ^−θ)2dσ2χ12。したがってスケーリングが n ではなく n になり、
n(g(θ^)−g(θ))d21g′′(θ)σ2χ12
要するに「g′(θ)=0 では極限が正規分布ではなく(スケールされた)カイ二乗分布になり、収束の速さも 1/n ではなく 1/n オーダーに速くなる」。g の接線が水平(極値)なので、θ^ がどちらにずれても g は同じ向き(g′′ の符号の側)に動く——これが分布が片側に寄った χ2 になる直観です。
⚠️ 試験で g′(θ)=0 となる点(g の極値)での分布を聞かれたら、正規ではなくカイ二乗が答え。g′(θ)2σ2 にそのまま代入して「分散0」と書くのは誤りです。
5. 試験での問われ方(1級)
理工学分野での1級の典型的な問われ方を論点ごとに整理します(出題範囲・配点は要最新確認)。
- 推定量の関数の標準誤差:θ^ の漸近分散が与えられ、g(θ^)(オッズ、対数、比、平均寿命 1/λ^ など)の漸近分散・標準誤差を g′(θ)2σ2 で計算させる。g′ を正しく微分し、θ に推定値を代入できるかが要点。
- 多変量デルタ法:2つ以上の推定量の関数(比 θ^1/θ^2、積、対数オッズ比など)について、勾配 ∇g を求め ∇g⊤Σ∇g を展開させる。共分散 σ12 の交差項を落とさないことがポイント。
- 分散安定化変換の導出:「分散が母数に依存する分布が与えられ、分散を一定にする変換を求めよ」という形。g′(θ)∝1/V(θ) を立て、積分して X / arcsinp^ / フィッシャーz を導く。変換後の分散が定数になることの確認まで。
- フィッシャーz変換の応用:相関係数の信頼区間・2つの相関の差の検定で、z=artanhr、Var(z)≈1/(n−3) を使って区間を作り、tanh で戻す手順。
- 漸近の前提の理解:デルタ法は「n が大きいときの近似」であり、有限標本では誤差が残ること。g′(θ)=0 では1次のデルタ法が使えず2次(χ2)になること。
6. 引っかけ・頻出論点
- ⚠️ g′(θ)=0 ではデルタ法(1次)は使えない:漸近分散 g′(θ)2σ2 が0になるのは「1次近似の破綻」のサイン。正しくは2次のデルタ法で n(g(θ^)−g(θ))→21g′′(θ)σ2χ12(正規ではなくカイ二乗、スケールも n)。「分散0」と答えるのは誤り。
- ⚠️ デルタ法は漸近(大標本)の近似:有限標本では正規からのずれ・バイアスが残る。特に g の曲率が大きい領域や θ^ の分散が大きい小標本では近似が悪い。「厳密に正規になる」は誤り。
- ⚠️ 多変量で共分散項を落とさない:g(θ^1,θ^2) の分散は ∇g⊤Σ∇g。θ^1,θ^2 が相関していれば交差項 2(∂1g)(∂2g)σ12 が効く。各変数の分散だけ足すのは誤り。
- ⚠️ 分散安定化は「分散を θ によらなくする」だけ:正規分布に完全に変換するわけではない(近似的に正規へ近づく副次効果はあるが、目的は等分散化)。「正規化変換」と「分散安定化変換」を混同しない。
- ⚠️ フィッシャーzの分散は 1/(n−3):1/n は素のデルタ法の値で、実用では補正版 1/(n−3) を使う。また r のまま正規近似してはいけない理由(ρ が ±1 付近で分散が潰れ分布が歪む)を説明できるように。
- ⚠️ SEは ∣g′(θ^)∣ を掛ける(2乗は分散側):標準誤差には傾きの絶対値を掛ける(SE(g(θ^))≈∣g′(θ^)∣SE(θ^))。分散には g′2、SEには ∣g′∣。混同しない。
よくある疑問(Q&A)
Q1. なぜ「1次テイラー展開」で済むのですか? 高次の項を無視していいのは何故?
漸近的に θ^ が真値 θ のごく近くにしかいないからです。n(θ^−θ) が有限の分布に収束するということは、θ^−θ 自体は 1/n のオーダーで0に潰れていく、という意味です。テイラー展開の2次項は (θ^−θ)2 のオーダー(1/n)で、n を掛けても 1/n→0 で消えます。一方1次項は (θ^−θ) のオーダー(1/n)で、n を掛けるとちょうど O(1) で生き残る。つまり「n 倍して見る」というスケールが1次項だけを拾うように設計されているのです。だから g′(θ)=0 である限り1次で十分。逆に g′(θ)=0 で1次が消えると、生き残るのは2次項になり、それが2次のデルタ法(第4節)です。
Q2. スルツキー定理は具体的に何をしてくれているのですか?
「確率収束する量と分布収束する量を、安心して掛け算・足し算してよい」ことを保証してくれます。デルタ法の途中で、傾き g′(θ~) は定数 g′(θ) に確率収束、n(θ^−θ) は正規分布に分布収束、と種類の違う収束が2つ出てきます。素朴には「収束先どうしを掛けて g′(θ)×N(0,σ2)」としたいところですが、それが本当に正しいか(分布収束の極限が壊れないか)は自明ではありません。スルツキー定理はまさに「片方が定数に確率収束するなら、その積は定数を掛けた分布収束になる」と言ってくれるので、g′(θ~)n(θ^−θ)dg′(θ)N(0,σ2) が厳密に正当化されます。デルタ法の証明はテイラー展開とスルツキー定理の二人三脚です。
Q3. 分散安定化変換と「正規化のための変換」は同じものですか?
目的が違います。分散安定化変換は「分散を母数 θ に依存させない(等分散にする)」のが目的で、g′(θ)∝1/V(θ) から導きます。一方「正規化変換」は「分布の形を正規に近づける」のが目的で、Box-Cox 変換などが代表です。両者はしばしば副次的に重なります(分散が安定すると分布も正規に近づきやすい)が、原理的には別物です。フィッシャーz変換は分散安定化として導かれますが、結果的に r の歪んだ分布をかなり正規に近づける効果も持つ、という具合に「両得」になることが多いだけで、定義上は分散安定化が主目的です。試験で「分散を一定にする変換」と問われたら 1/V の積分、「正規に近づける」と問われたら別系統、と切り分けてください。
Q4. ポアソンの X で「分散が 1/4」になるのに、なぜ 2μ ではなく X を使うのですか?
積分から出る変換は g(μ)=2μ ですが、定数倍は分散安定化の本質に影響しないからです。g を c 倍すると傾きも c 倍、分散は c2 倍になりますが、「θ によらず一定」という性質は保たれます。2μ なら分散 ≈1、μ なら分散 ≈1/4 で、どちらも定数。実務では扱いやすい X(係数1)を使うのが普通で、そのときの分散が 1/4 になる、というだけです。試験では「変換の形( か arcsin か artanh か)」が問われるので、定数倍は気にせず関数形を答えれば十分なことが多いです。
Q5. g′(θ)=0 で χ2 が出るのは、現実にどんな場面ですか?
g が真値 θ で**極値(山か谷)**を取る場合です。たとえば g(θ)=θ2 を θ=0 で評価すると g′(0)=0。θ^ が0の左右どちらにずれても g(θ^)=θ^2≥0 で必ず正の側に動くので、g(θ^)−g(0) の分布は0以上に偏った非対称な分布になる——それが(正規の2乗である)χ12 をスケールしたものです。より実践的には、ある統計量がパラメータ空間の境界や対称点で評価されるとき(尤度比検定統計量が帰無の境界で χ2 混合になる現象などと地続き)に現れます。1級では「g′=0 なら正規でなく χ2、スケールは n」という結論を押さえておけば十分です。
まとめ
- デルタ法:n(θ^−θ)dN(0,σ2) かつ g′(θ)=0 なら n(g(θ^)−g(θ))dN(0,g′(θ)2σ2)。導出は「1次テイラー展開で g を接線に置き換え、傾き g′(θ~) をスルツキー定理で g′(θ) に差し替える」。実用は SE(g(θ^))≈∣g′(θ^)∣SE(θ^)。
- 多変量デルタ法:g′(θ) が勾配 ∇g に、g′(θ)2σ2 が2次形式 ∇g(θ)⊤Σ∇g(θ) に置き換わる。比や積では共分散の交差項を落とさない。ベクトル値関数ならヤコビ行列 J で JΣJ⊤。
- 分散安定化変換:漸近分散 V(θ) が θ に依存するとき、g′(θ)∝1/V(θ)、すなわち g(θ)=∫dθ/V(θ) で分散を定数化。ポアソン V=μ⇒X(分散 1/4)、二項比率 V=p(1−p)⇒arcsinp^(分散 1/(4n))、相関 V=(1−ρ2)2⇒ フィッシャーz 21ln1−r1+r(分散 1/n、補正 1/(n−3))。3つとも同じ1本の積分から出る。
- 2次のデルタ法:g′(θ)=0 なら1次は使えず、n(g(θ^)−g(θ))d21g′′(θ)σ2χ12。極限は正規ではなくカイ二乗、収束スケールは n ではなく n。
- 注意:デルタ法は漸近近似(有限標本では誤差が残る)。分散安定化は等分散化が目的で正規化とは別物。SEには ∣g′∣、分散には g′2。
関連ノート