🎓 レベル:基礎 | 重要度:A(必須)
📎 前提:ナイーブベイズ(生成的分類器の例)
要点(BLUF)
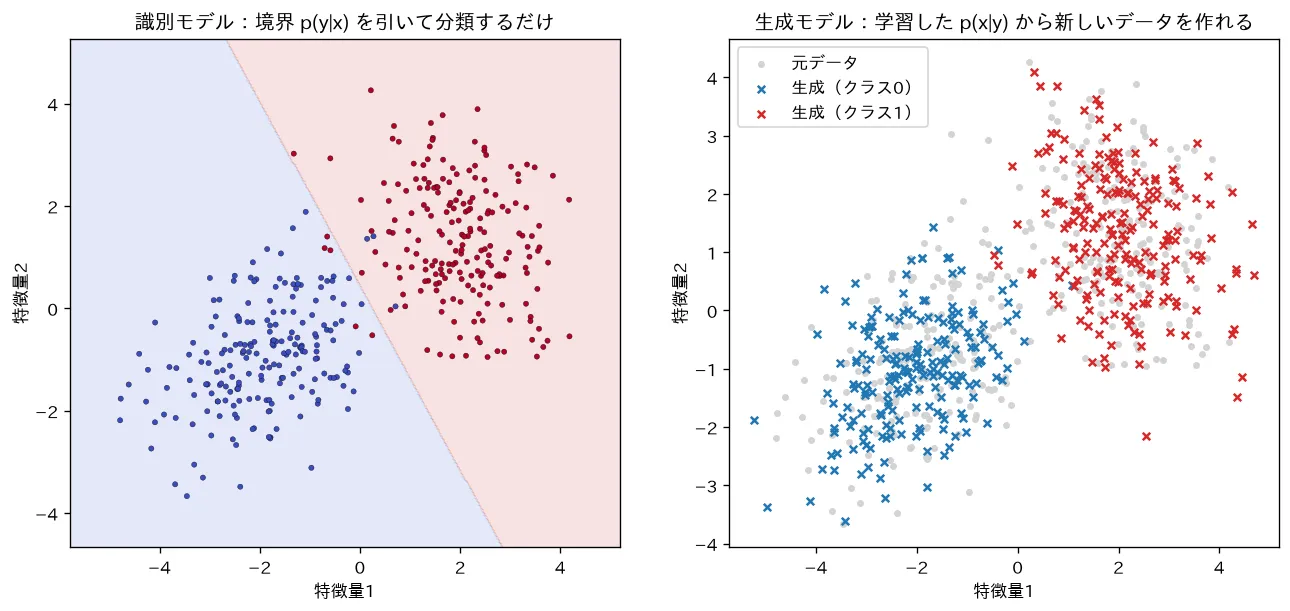
- 生成モデルは「データそのものの分布 (ラベル付きなら )を学ぶ」モデルです。分布が手に入れば、そこから新しいデータをサンプリングできるのが識別モデルとの決定的な違いです。
- 識別モデルが「境界を引く」( だけ学ぶ)のに対し、生成モデルは「データがどう生まれるかを丸ごと説明する」。だから生成・異常検知・欠損補完・表現学習まで幅広く使えます。
- 学習の基本は の最尤推定ですが、高次元では尤度の計算もサンプリングも難しく、その「難しさへの対処の仕方」で VAE・GAN・自己回帰・フロー・拡散モデルに分かれます。
1. 識別モデル vs 生成モデル
機械学習の確率モデルは、何の分布を学ぶかで大きく2つに分かれます。
| 識別モデル(discriminative) | 生成モデル(generative) | |
|---|---|---|
| 学ぶ分布 | (条件付き) | または (同時) |
| やること | class の境界を引く | データの分布そのものを説明 |
| サンプリング | できない | できる(これが本質) |
| 代表例 | ロジスティック回帰、SVM、多くのNN分類器 | ナイーブベイズ、判別分析(LDA・QDA)、混合ガウスモデルとEM、VAE/GAN/拡散 |
識別モデルは「 を見て を当てる」ことだけに集中します。 がそもそもどう分布しているか()には興味がありません。境界さえ引ければ分類はできるからです。
生成モデルは逆に、 がどう分布しているかを学びます。ラベル付き問題なら同時分布 を学び、ベイズの定理で事後確率を作って分類します:
要するに:識別モデルは「ねこ と いぬ の間に線を引く」係、生成モデルは「ねこ画像はこういう分布、いぬ画像はこういう分布」と各クラスの見た目そのものを覚える係です。線を引くだけなら後者は遠回りに見えますが、分布を持っているぶん新しいねこを描けるのが強みです。
ナイーブベイズ が「生成的分類器」と呼ばれるのはまさにこれで、 を作ってからベイズで に変換しています。一方 ロジスティック回帰 は を直接モデリングする識別側の代表です。
2. 生成モデルで何ができるか
分布 (または )が手に入ると、分類以外にも次のことができます。
- 新規サンプリング(生成): で、学習データに無い新しいデータを作る。画像・音声・テキスト生成の核です。
- 密度推定(異常検知):ある の が極端に小さければ「見たことのない=異常」と判定できる(→ 異常検知 と同じ発想)。
- 欠損補完(inpainting / imputation):一部が欠けた に対し、残りで条件づけた条件付き分布からもっともらしい値を埋める。
- 表現学習: をうまく説明する潜在変数 を学ぶ過程で、データの圧縮された意味的表現が得られる(VAE の潜在空間など)。
識別モデルは1番目(生成)が原理的にできません。「 を持っていない」からです。ここが生成モデルを学ぶ最大の動機になります。
3. 尤度 を最尤で学ぶ — そして高次元の壁
生成モデルの学習は、基本的に ナイーブベイズ と同じ最尤推定です。パラメータ を持つモデル で、データ の対数尤度を最大化します:
要するに:「手元のデータが一番出やすくなるように分布の形を調整する」だけです。考え方はナイーブベイズの 推定と何も変わりません。
ところが が高次元(数百×数百の画像など)になると、ここに2つの壁が立ちます。
- 尤度 がそもそも計算できない。確率分布は全体で積分1の正規化が要りますが、 を保つ正規化定数が高次元では手に負えないことが多い。
- サンプリングが難しい。仮に分布の形が分かっても、 で実際にもっともらしいサンプルを引く操作が高次元では非自明です。
この**「尤度をどう扱うか」「サンプリングをどう実現するか」の答え方**こそが、生成モデルを分類する軸になります。
4. 分類地図:明示的尤度 vs 暗黙的
生成モデルは大きく、尤度 を陽に(明示的に)扱うか/扱わないかで分かれます。
graph TD G["生成モデル<br/>p(x) を学ぶ"] --> E["明示的尤度<br/>p(x) を式として持つ"] G --> I["暗黙的<br/>p(x) は計算せずサンプルだけ作る"] E --> EX["厳密に計算できる"] E --> AP["近似で扱う"] EX --> AR["自己回帰モデル<br/>連鎖律で厳密分解"] EX --> FL["フローベース<br/>可逆変換で厳密"] AP --> VAE["VAE<br/>下界 ELBO で近似"] AP --> DIff["拡散モデル<br/>段階的ノイズ除去"] I --> GAN["GAN<br/>識別器との敵対学習"]
各枝を一言ずつ整理します。
- 明示的・厳密
- 自己回帰モデル:同時分布を連鎖律で と厳密に分解し、各因子を順に予測します。尤度が正確に計算できるのが強み(GPT 系の言語モデルもこの枠)。生成は1要素ずつなので遅い。
- フローベース:可逆な変換で単純分布(ガウス)を複雑分布に写し、変数変換公式(ヤコビアン)で尤度を厳密に得ます。可逆性のためアーキテクチャに強い制約がかかります。
- 明示的・近似
- オートエンコーダとVAE:尤度を直接最大化できないので、計算可能な**下界(ELBO)**を最大化します。 という不等式が核で、潜在変数 を介して生成します。
- 拡散モデル:データに少しずつノイズを加える過程の逆過程を学び、純ノイズから段階的に復元してサンプリングします。これも変分下界の枠で学習でき、現在の画像生成の主力です。
- 暗黙的
- 敵対的生成ネットワーク(GAN): を式として一切持たず、生成器がサンプルを作り、識別器が本物と見分けようとする敵対ゲームだけで学習します。尤度を計算しないので評価指標は別途必要、学習も不安定(モード崩壊など)になりがちですが、サンプルの質は高くできます。
flowchart LR Z["潜在 / ノイズ z"] --> Gen["生成器"] Gen --> X["生成サンプル x"] Real["本物データ"] --> Disc["識別器"] X --> Disc Disc --> J["本物 / 偽物 の判定"] J -.->|"敵対的な学習信号"| Gen
要するに:明示的モデルは「分布の数式を持つので尤度で評価でき、密度推定や異常検知にも使える」。暗黙的モデル(GAN)は「数式は持たないがサンプルだけは上手に作る」。この差が用途の差に直結します。
5. 生成 vs 識別のトレードオフ
「分類したいだけ」なら、わざわざ まで学ぶ生成モデルは遠回りです。実際、純粋な分類性能では識別モデルの方が有利なことが多い。理由は、識別モデルは境界だけに資源を集中でき、 という余計な部分のモデル化ミスに引きずられないからです。
一方で生成モデルには次の利点があります(→ 古典的には ナイーブベイズ vs ロジスティック回帰 の比較が典型)。
- 少データに強いことがある:生成側(ナイーブベイズ)は強い分布仮定を置くぶん、少ないデータでも素早く「それなりの」推定に収束します。識別側(ロジスティック回帰)はデータが十分あれば最終的に勝ちますが、収束に必要なデータ量が多い傾向があります(Ng & Jordan の古典的な比較)。
- 情報が豊富:分布そのものを持つので、生成・補完・異常検知・半教師あり学習など分類以外に展開できます。
graph LR D["識別モデル<br/>p(y|x)"] --> Dp["分類は得意<br/>境界に集中"] D --> Dm["生成はできない"] Gn["生成モデル<br/>p(x) , p(x,y)"] --> Gp["生成・補完・異常検知<br/>少データに強いことも"] Gn --> Gm["学習が難しい<br/>分類だけなら遠回り"]
要するに:「とにかく当てたい」なら識別、「データそのものを理解・生成したい/使える情報を増やしたい」なら生成、という棲み分けです。
⚠️ よくある誤解・落とし穴
- 「生成モデル=GAN」ではありません。 GAN は生成モデルの**一種(暗黙的密度モデル)**にすぎません。自己回帰・VAE・フロー・拡散はいずれも生成モデルで、しかも GAN と違って尤度を陽に扱います。むしろ現在の画像生成の主力は拡散モデル、テキスト生成は自己回帰(LLM)です。
- 「生成モデルの方が分類も強い」とは限りません。 前述のとおり、データが十分あるときの純粋な分類性能では識別モデルが上回ることが多いです。生成モデルの強みは分類性能そのものではなく「分布を持っていること」から来る応用の広さです。
- 「尤度(log-likelihood)が高い=良いサンプル」ではありません。 高次元では、対数尤度の高さとサンプルの見た目の質はほぼ独立になり得ます。高尤度なのに汚いサンプルを出すモデルも、低尤度なのに綺麗なサンプルを出すモデルも構成できることが知られています(Theis et al., 2016)。そのため生成モデルは「使いたい用途に即した指標」で別途評価すべきです。
- **「生成的分類器は を捨てない」**点に注意。識別モデルが を無視できるのは「比較に効かないから」。生成的分類器はあえて を作るので、その分布仮定が間違っていると分類も歪みます(ナイーブベイズの条件付き独立仮定が典型)。
6. 対応するシミュレーション
simulations/generative_vs_discriminative.py:識別モデル(ロジスティック回帰)は境界 だけを学んで分類するのに対し、生成モデル(クラスごとのガウス )はデータの“作られ方”を学ぶので、そこから新しいデータをサンプリングできることを可視化します。分類だけなら識別モデルが高精度なことが多い一方、生成・欠損補完・異常検知は生成モデルの強み。VAE・GAN・拡散はこの「 を学んで生成」を高次元で行う発展形です(オートエンコーダとVAE)。
関連ノート
- ドメイン目次:生成モデル 目次
- 主要な生成モデル:オートエンコーダとVAE・敵対的生成ネットワーク・自己回帰モデル
- 生成的分類器の例:ナイーブベイズ・判別分析(LDA・QDA)
- 密度ベースの分布学習:混合ガウスモデルとEM
- 全体像:機械学習テキスト 全体目次